3.7.1 Classic TCP Congestion Control
Classic TCP Congestion Control은 TCP가 네트워크 혼잡 상황에서 데이터를 어떻게 송신 속도를 조정하며 안정적인 전송을 보장하는지 설명하는 핵심적인 메커니즘이다.
TCP는 네트워크 혼잡이 감지되었을 때 송신 속도를 줄이고, 혼잡이 해소되었다고 판단되면 송신 속도를 점진적으로 증가시키는 과정을 통해 혼잡을 관리한다.
TCP 송신 속도 제한 방법
TCP 송신자는 네트워크 혼잡을 방지하기 위해 송신 속도를 제한한다. 이를 위해 다음과 같은 핵심 변수들이 사용된다:
• Congestion Window (cwnd):
송신자가 네트워크에 보내는 데이터의 양을 제어하는 주요 변수이다. cwnd의 값은 혼잡 상태에 따라 증가하거나 감소한다.
• Receive Window (rwnd):
수신자의 버퍼 상태를 반영하는 값으로, 송신자가 한 번에 보낼 수 있는 최대 데이터를 제한한다.
• 송신자는 전송 가능한 데이터의 양을
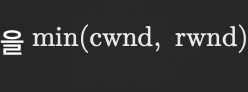
로 계산한다.
즉, 송신자는 cwnd와 rwnd 중 작은 값을 기준으로 전송량을 제한하며, 이 값은 데이터의 수신 확인(ACK) 속도에 따라 동적으로 변화한다.
혼잡의 감지 방법
TCP는 송신 경로에서 혼잡이 발생했는지 다음 두 가지 방법으로 감지한다:
1. Timeout 발생: 데이터가 특정 시간(Timeout) 내에 ACK를 받지 못하면 혼잡이 발생했다고 간주한다.
2. Duplicate ACKs: 동일한 ACK가 3번 이상 반복되면 특정 패킷이 손실되었음을 의미하며, 이를 Triple Duplicate ACK라고 한다.
혼잡을 감지한 TCP는 송신 속도를 줄이고 네트워크 부하를 완화하려 한다.
TCP 혼잡 제어의 단계 및 알고리즘
Classic TCP Congestion Control은 혼잡 상황에 대응하기 위해 세 가지 주요 단계로 작동한다.
1. Slow Start (지수적 증가 단계)
• 연결 시작 시, cwnd는 일반적으로 1 MSS(최대 세그먼트 크기)로 설정된다.
• 수신된 ACK마다 cwnd를 1 MSS씩 증가시키며, 각 RTT(Round Trip Time)마다 cwnd는 두 배로 증가한다.
• 이 단계의 목표는 네트워크 용량을 빠르게 탐색하면서도 혼잡을 방지하는 것이다.
• 종료 조건:
• cwnd가 ssthresh(slow start threshold) 값에 도달하거나,
• 데이터 손실(Timeout 또는 Triple Duplicate ACK)이 발생하면 Slow Start를 종료한다.

예시:
Figure 3.50은 TCP Slow Start 단계의 작동을 보여준다. 한 RTT 내에 1개의 세그먼트를 보내 ACK를 받으면, 다음 RTT에 2개의 세그먼트를 보낸다. 이후 4개, 8개 등으로 증가한다. 이를 통해 cwnd는 네트워크 용량을 초과하지 않는 범위에서 빠르게 증가한다.
2. Congestion Avoidance (선형 증가 단계)
• Slow Start 단계에서 cwnd가 ssthresh를 초과하면 Congestion Avoidance 단계로 전환한다.
• 이 단계에서는 cwnd를 더 보수적으로 증가시킨다:
• 매 ACK 수신 시 cwnd는 MSS 단위로 선형 증가한다. 즉, 한 RTT 동안 cwnd는 1 MSS만 증가한다.
• 종료 조건:
• 데이터 손실(Timeout 또는 Triple Duplicate ACK)이 발생하면 Congestion Avoidance는 종료되고, cwnd가 감소한다.
예시:
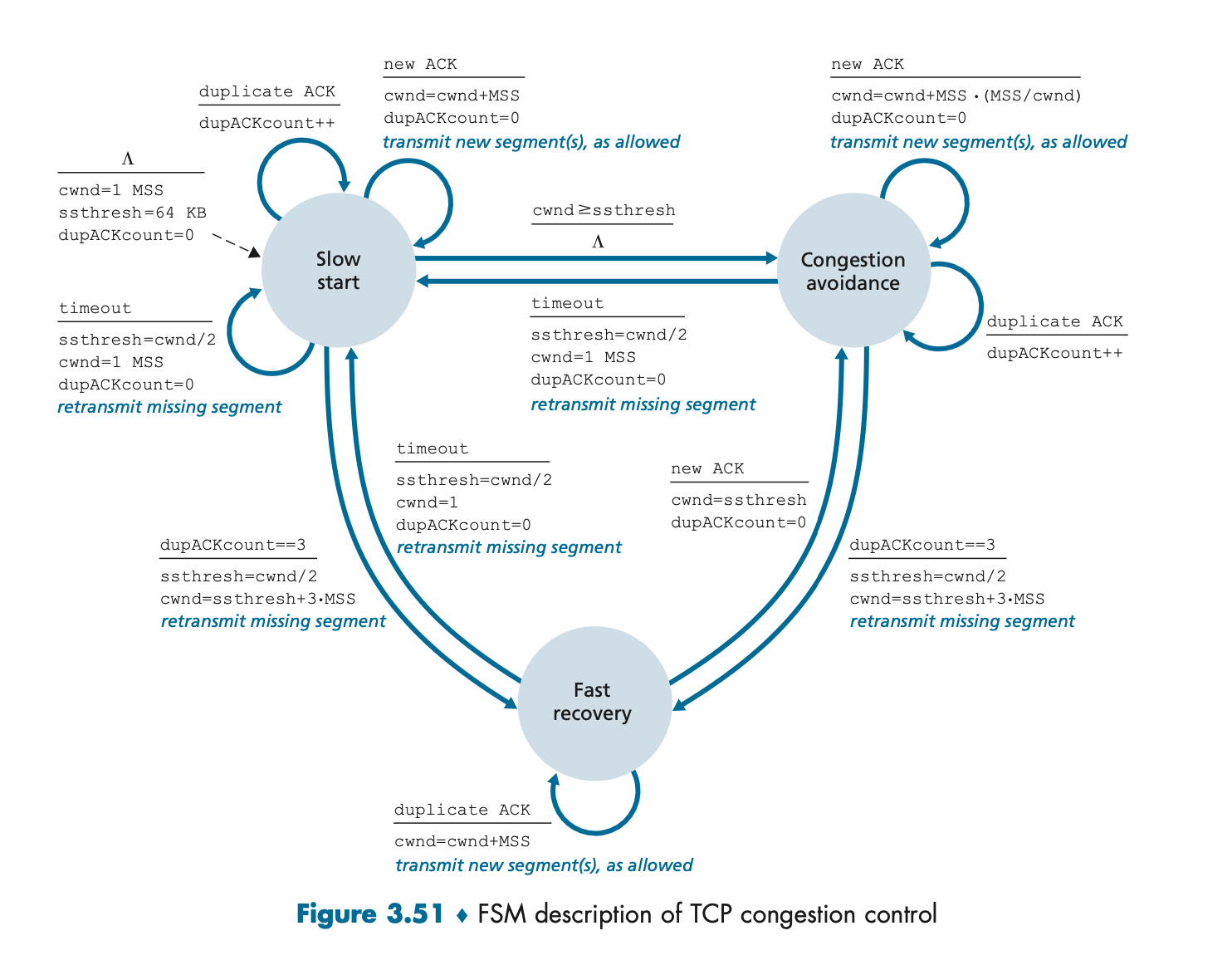
Figure 3.51의 FSM(Finite State Machine)은 TCP의 상태 전환 과정을 시각적으로 보여준다. Congestion Avoidance 단계에서는 송신 속도가 안정적으로 증가하지만, 손실이 발생하면 Slow Start로 돌아가거나 Fast Recovery로 이동한다.
3. Fast Recovery (빠른 복구 단계)
• Triple Duplicate ACK가 발생했을 때만 동작하며, Timeout보다 빠르게 네트워크를 복구하는 방법이다.
• cwnd는 손실이 발생한 순간 절반으로 감소되며, 이후 빠르게 증가한다:
• 수신된 각 Duplicate ACK마다 cwnd를 1 MSS씩 증가시켜 네트워크가 정상 상태로 돌아오는 속도를 높인다.
• ACK가 손실된 세그먼트를 확인하면, Fast Recovery를 종료하고 Congestion Avoidance로 전환한다.
예시:
Figure 3.51의 FSM에서 Triple Duplicate ACK 이벤트가 발생하면, Slow Start로 가지 않고 Fast Recovery로 진입한다. 이를 통해 네트워크 혼잡을 효율적으로 해결한다.
혼잡 제어 알고리즘의 동작 예시
TCP Tahoe와 TCP Reno
• TCP Tahoe: 손실 발생 시 cwnd를 1 MSS로 설정하고, Slow Start로 돌아간다.
• TCP Reno: 손실 발생 시 Fast Recovery를 적용하여 성능을 개선한다. Slow Start로 돌아가지 않고 cwnd를 절반으로 줄이며, 더 빠른 복구를 수행한다.

예시:
Figure 3.52는 TCP Tahoe와 TCP Reno의 cwnd 변화를 보여준다. Reno는 Tahoe에 비해 손실 이후 더 빠르게 네트워크 상태를 복구하며, Slow Start로 전환하지 않는다.
혼잡 제어의 성능 최적화: AIMD와 TCP Cubic
AIMD (Additive Increase, Multiplicative Decrease)

• cwnd를 선형적으로 증가시키며(Additive), 손실 발생 시 배율로 감소(Multiplicative)한다.
• Figure 3.53은 AIMD 알고리즘이 네트워크에서 “톱니형” 혼잡 창 변화를 생성하는 모습을 보여준다.
TCP Cubic
• TCP Reno와 비교하여 빠르게 송신 속도를 회복하는 알고리즘이다.

• 혼잡 창을 큐브 함수로 조정하여 대역폭 탐색을 가속화한다. Figure 3.54는 Cubic이 TCP Reno보다 더 높은 송신 속도를 달성하는 과정을 보여준다.

요약
Classic TCP Congestion Control은 네트워크의 혼잡 상황에 따라 송신 속도를 조절하는 기본적인 방법이다. 이를 통해 네트워크 자원을 효율적으로 활용하며, 데이터 손실과 지연을 최소화한다. TCP Tahoe와 Reno는 이러한 메커니즘의 진화된 버전으로, 혼잡 상황에서 더욱 효과적인 복구 및 속도 조정을 제공한다.
3.7.2 Network-Assisted Explicit Congestion Notification and Delayed-based Congestion Control
Explicit Congestion Notification (ECN)
TCP와 IP는 RFC 3168을 통해 ECN(Explicit Congestion Notification) 메커니즘을 지원하도록 확장되었다.
ECN은 네트워크에서 발생하는 혼잡을 수동적인 패킷 손실 감지가 아니라, 네트워크 레벨에서 직접적으로 혼잡 상태를 통지하는 메커니즘을 제공한다.
1. ECN 비트의 구조:
IP 데이터그램 헤더의 Type of Service(TOS) 필드에 두 개의 ECN 비트가 포함된다. ECN 비트의 4가지 설정은 다음과 같은 의미를 가진다:
• 00: ECN 비활성화
• 01, 10: ECN 활성화 및 혼잡 상태 아님
• 11: 혼잡 상태 존재
혼잡 상태를 나타내는 11은 네트워크 장치(예: 라우터)가 혼잡을 감지하면 설정된다.
2. ECN 처리 과정:
• 혼잡 라우터는 IP 데이터그램의 ECN 비트를 11로 설정하여 혼잡 상태를 수신지에 알린다.
• 수신 호스트는 이 정보를 TCP ACK에 포함된 ECE(Explicit Congestion Notification Echo) 비트를 통해 송신 호스트에 전달한다.
• 송신 호스트는 이를 수신하고 혼잡 창(cwnd)을 줄이는 방식으로 혼잡에 대응한다. 이는 손실 이벤트나 재전송보다 빠른 혼잡 감지 및 반응을 가능하게 한다.
3. 관련 프로토콜의 적용:
ECN은 TCP 외에도 데이터 센터와 같은 환경에서 DCQCN(Data Center Quantized Congestion Notification)과 같은 다양한 혼잡 제어 프로토콜에 활용된다. ECN의 효과적인 구현은 네트워크의 전반적인 효율성을 높인다.
Delay-Based Congestion Control
지연 기반 혼잡 제어는 패킷 손실이 발생하기 전에 혼잡 상태를 감지하기 위해 지연을 활용한다. 이 접근법은 혼잡으로 인해 발생하는 지연 증가를 기반으로 혼잡을 탐지하고 이를 완화한다.
1. TCP Vegas:
TCP Vegas는 RTT(Round Trip Time)를 사용하여 혼잡을 사전에 감지한다.
• RTT 측정:
송신자는 모든 패킷의 RTT를 측정하고 최저 RTT() 값을 기준으로 경로가 혼잡하지 않은 상태의 예상 처리량을 계산한다.
• 혼잡 탐지:
측정된 실제 처리량이 예상 처리량보다 작다면 경로가 혼잡하다는 신호로 간주하고 송신 속도를 줄인다.
• 혼잡 완화:
예상 처리량에 가까운 처리량이 감지되면, 송신 속도를 증가시켜 네트워크 자원을 더 활용한다.
2. “Pipe Just Full” 직관:
TCP Vegas는 “파이프를 가득 채우되 더 이상은 채우지 말라”는 직관에 기반한다. 이는 병목 구간의 링크 대역폭을 완전히 활용하되, 불필요한 대기열 증가를 피하려는 것이다.
BBR Congestion Control
BBR(Bottleneck Bandwidth and RTT)는 TCP Vegas의 아이디어를 발전시킨 혼잡 제어 알고리즘으로, RTT와 대역폭을 분석하여 최대 처리량을 달성한다. BBR은 Google에서 사용되며, 기존의 TCP CUBIC보다 더 나은 성능을 제공하는 것으로 알려져 있다.
BBR은 다음과 같은 특징을 가진다:
• 혼잡 회피: 지연 증가를 피하며 대역폭을 활용.
• 광범위한 배포: BBR은 대규모 데이터 센터와 고속 네트워크에서 채택되고 있다.

결론
ECN과 지연 기반 혼잡 제어는 TCP 혼잡 제어 메커니즘의 한계를 보완하며, 네트워크 자원의 효율적인 사용과 지연 최소화를 목표로 한다. 특히, ECN은 패킷 손실 없이 혼잡을 신속히 감지할 수 있고, TCP Vegas와 같은 지연 기반 제어는 대역폭 활용을 극대화하면서 혼잡을 줄이는 데 기여한다.
3.7.3 Fairness
1. Fairness란?
• Fairness란 네트워크에서 여러 TCP 연결이 공평하게 대역폭을 나눠 가지는 것을 의미한다.
• 예를 들어, 개의 TCP 연결이 병목 링크(bottleneck link) 대역폭 bps를 공유하는 경우, 각 연결이 이상적으로 받을 수 있는 대역폭은 이다.
• 모든 연결이 동일한 조건으로 대역폭을 사용하는 것을 목표로 하지만, 실제 네트워크에서는 여러 변수로 인해 공평성이 깨질 수 있다.
2. AIMD와 Fairness
• TCP는 AIMD(Additive Increase, Multiplicative Decrease) 방식을 통해 공평성을 유지하려고 한다.
• Additive Increase (덧셈 증가)
• 네트워크가 혼잡하지 않을 때, TCP는 혼잡 윈도우(cwnd)를 점진적으로 증가시켜 전송 속도를 늘린다.
• Multiplicative Decrease (곱셈 감소)
• 네트워크에 혼잡이 발생하면, TCP는 혼잡 윈도우를 대폭 줄여 혼잡을 완화한다.
• 이러한 방식은 여러 TCP 연결이 병목 링크를 공유할 때, 자연스럽게 공평한 대역폭 분배를 가능하게 한다.
3. 두 TCP 연결 간의 공평성
• 두 개의 TCP 연결이 동일한 병목 링크를 공유하는 경우를 예로 들어보자.
• 각 연결의 전송 속도는 혼잡 윈도우(cwnd)에 의해 결정된다.
• 두 연결이 병목 대역폭 을 공평하게 나누려면, 각 연결의 처리량이 근처에서 균형을 이루어야 한다.

그림 설명
• A 지점: 두 연결이 전송 속도를 증가시키며 초기 대역폭을 점차적으로 활용하는 단계이다.
• B 지점: 두 연결이 병목 링크 용량을 초과하는 데이터를 전송하여 혼잡이 발생하는 시점이다.
• C 지점: 혼잡 이후, 전송 속도가 감소하며 다시 공평성을 찾아가는 단계이다.
• 이러한 과정이 반복되며, 두 연결은 점차적으로 공평한 대역폭을 나누게 된다.
4. UDP와 공평성 문제
• TCP는 AIMD를 통해 공평성을 유지하려고 하지만, UDP는 그렇지 않다.
• UDP는 혼잡 제어를 수행하지 않으며, 네트워크 상태와 상관없이 일정한 속도로 데이터를 전송한다.
• 예를 들어, 비디오 스트리밍 같은 애플리케이션은 네트워크 혼잡 상황에서도 전송 속도를 줄이지 않고 계속 데이터를 보낸다.
• 이로 인해 UDP 트래픽이 TCP 트래픽을 밀어내고, 불공평하게 대역폭을 독점하는 상황이 발생할 수 있다.
해결 방법
• UDP의 대역폭 독점을 막기 위해, 공평 대기(Fair Queuing)와 같은 기술이 제안되었다.
5. 병렬 TCP 연결과 공평성
• 일부 애플리케이션은 여러 병렬 TCP 연결을 생성하여 더 많은 대역폭을 차지하려고 한다.
• 웹 브라우저는 여러 객체를 동시에 다운로드하기 위해 병렬 TCP 연결을 사용한다.
• 예를 들어, 병목 링크의 대역폭이 이고, 기존 애플리케이션들이 각각 1개의 TCP 연결을 사용해 대역폭을 씩 나눠 쓰고 있는 상황을 가정해 보자.
• 이때 새로운 애플리케이션이 10개의 병렬 TCP 연결을 사용하면, 이 애플리케이션은 병목 대역폭의 절반 이상을 차지하게 된다.
• 이러한 문제로 인해 병렬 TCP 연결은 공평성을 해치는 요인이 될 수 있다.
이와 같은 방식으로 TCP는 공평성을 확보하려 하지만, UDP나 병렬 연결 같은 변수로 인해 공평성이 깨지는 문제가 존재한다.
'Book > COMPUTER NETWORKING A TOP-DOWN-APPROACH' 카테고리의 다른 글
| 4.2 What's Inside a Router? (0) | 2024.12.03 |
|---|---|
| 4.1 An Overview of Network Layer (4) | 2024.12.03 |
| 3.6 Principles of Congestion Control (0) | 2024.11.24 |
| 3.5 Connection-Oriented Transport: TCP (0) | 2024.11.24 |
| CH3_Transport Layer (2) | 2024.10.19 |