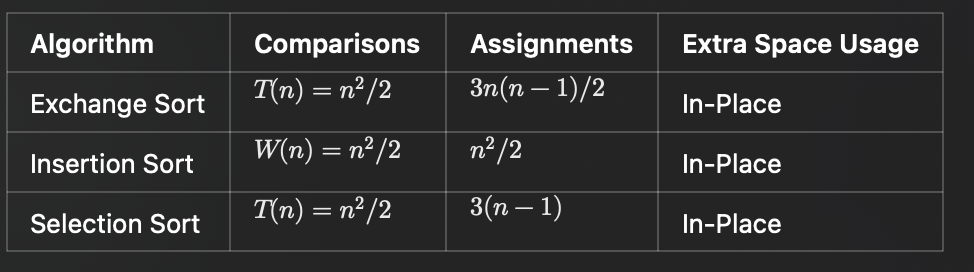
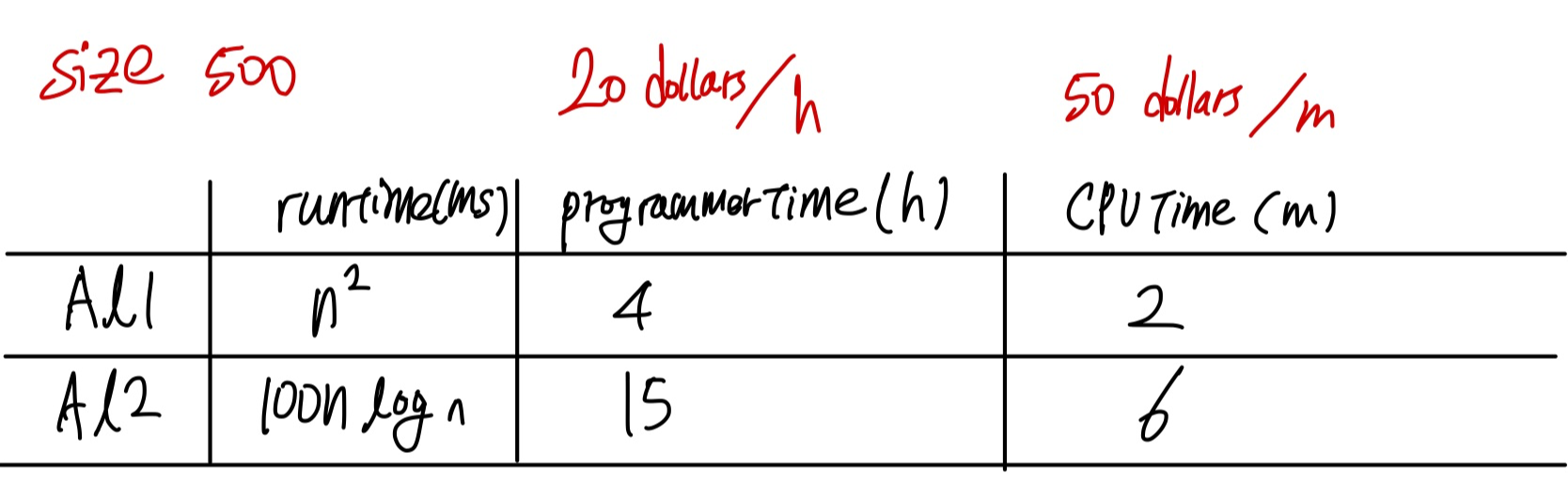8.1 Lower Bounds for Searching Only by Comparisons of Keys 이 섹션에서는 키 비교만을 사용하여 배열에서 특정 키를 검색할 때 소모되는 최악의 경우 비교 횟수의 하한을 다룹니다.특히, Binary Search와 Sequential Search의 의사결정 트리(Decision Tree)를 사용하여 검색 과정의 효율성을 분석합니다. 의사결정 트리 (Decision Tree) • 정의:의사결정 트리는 키 를 배열에서 검색하는 과정에서 발생하는 모든 비교를 나타냅니다. • 각 내부 노드는 키 비교를 나타냅니다. • 각 리프 노드는 검색 결과를 나타냅니다 (성공적으로 검색된 위치 또는 실패). • 예시: • Figure 8.1: 정렬된 배열에서 이진 탐색(Binary ..