3.1 Introduction and Transport-Layer Service
3.1.1 전송 계층과 네트워크 계층의 관계
전송 계층은 네트워크 계층 바로 위에 있으며, 두 계층의 역할이 다소 비슷해 보이지만 중요한 차이점이 있다. 이를 쉽게 이해하기 위해 집과 우편 서비스에 비유해서 설명할 수 있다.

• 네트워크 계층: 두 집 사이에서 편지를 보내는 우편 서비스와 같다. 우편 서비스는 집에서 집으로 편지를 배달하는 일을 담당한다.
• 전송 계층: 집 안에서 각 아이들 간의 편지를 모아서 배달하는 역할을 하는 **사람(Ann과 Bill)**과 같다. 이들은 각 집 안에서 형제자매들로부터 편지를 모아 우편 서비스에 전달하고, 다시 도착한 편지를 각 사람에게 나눠준다.
이 비유에서 보듯, 네트워크 계층은 호스트 간(집과 집 사이)의 논리적 통신을 제공하며, 전송 계층은 애플리케이션 프로세스(사람들 간) 간의 통신을 처리한다. 전송 계층은 애플리케이션 메시지를 받아 이를 네트워크 계층에 전달하고, 네트워크 계층은 이를 물리적으로 전달해준다.
중요한 점은, 네트워크 계층은 메시지를 전달할 때 전송 계층에서 추가한 정보(예: 각 애플리케이션의 목적지)를 신경 쓰지 않고, 오직 네트워크 패킷에 있는 정보만을 사용한다는 것이다. 즉, 중간에 있는 라우터들은 전송 계층의 세부 정보를 보지 않고, 오직 네트워크 계층 정보만을 처리한다.
3.1.2 인터넷에서의 전송 계층 개요
인터넷에서는 두 가지 전송 계층 프로토콜이 있다:
1. UDP(유저 데이터그램 프로토콜): 신뢰성을 보장하지 않고 연결을 설정하지 않는 비연결형 프로토콜이다. 데이터가 도착하는지, 제대로 도착하는지는 보장하지 않는다.
2. TCP(전송 제어 프로토콜): 신뢰성과 순서를 보장하는 연결형 프로토콜이다. 데이터를 정확한 순서로 전달하며, 데이터가 도착하지 않으면 재전송하는 등의 기능을 제공한다.
TCP와 UDP는 모두 전송 계층에서 네트워크 계층의 IP 프로토콜 위에서 동작한다. IP는 호스트 간의 논리적인 통신을 제공하지만, 신뢰성이나 순서는 보장하지 않는다. IP는 데이터를 최선의 노력으로 전달하는 best-effort 서비스이며, 데이터가 손실되거나 순서가 바뀔 수 있다.
UDP는 IP의 이러한 특성을 그대로 이어받아 신뢰성 없이 데이터를 전송하지만, TCP는 IP의 불완전한 서비스를 신뢰성 있는 서비스로 변환해준다. TCP는 데이터를 올바르게, 순서대로 전달하고, 손실된 경우 재전송을 통해 보완한다. 또한 TCP는 혼잡 제어를 통해 네트워크가 과부하 상태에 빠지지 않도록 관리하는 역할도 한다. 반면, UDP는 이러한 제어가 없기 때문에 네트워크에 과부하를 일으킬 수도 있다.
이로써 전송 계층의 개념과 역할을 쉽게 설명했다. 전송 계층은 애플리케이션 프로세스 간의 통신을 처리하며, 신뢰성 있는 서비스(TCP)와 빠른 전송(UDP) 중 하나를 선택할 수 있는 중요한 계층이다 .
3.2 Multiplexing and Demultiplexing
다중화와 역다중화란?
• 다중화(Multiplexing): 송신 측에서 여러 프로세스의 데이터를 하나의 통신 경로로 결합하는 작업을 의미한다. 각 프로세스는 소켓을 통해 데이터를 전송하며, 각 데이터는 네트워크 계층에서 전송할 수 있도록 세그먼트로 묶인다.
• 역다중화(Demultiplexing): 수신 측에서 받은 세그먼트를 각 소켓으로 나누어 올바른 프로세스로 전달하는 작업이다. 즉, 하나의 통신 경로로 받은 데이터를 여러 프로세스로 분배하는 것이다.
예시: 여러 네트워크 애플리케이션 처리
컴퓨터에서 여러 애플리케이션을 동시에 실행한다고 가정하자. 예를 들어, 웹 페이지를 다운로드하면서 FTP 세션 하나와 텔넷 세션 두 개를 동시에 실행 중이라고 하자. 이 경우 총 네 개의 네트워크 애플리케이션이 실행되고 있는 것이다.
이때, 네트워크 계층에서 데이터를 받을 때, 전송 계층은 이 데이터를 올바른 애플리케이션(프로세스)으로 전달해야 한다. 그렇다면 전송 계층은 어떻게 이를 처리할까?
소켓과 포트 번호
각 애플리케이션 프로세스는 소켓을 가지고 있다. 소켓은 네트워크에서 데이터를 주고받을 수 있는 창구 역할을 한다. 각 소켓은 포트 번호라는 고유한 식별자를 가지고 있으며, 이 번호를 통해 전송 계층은 수신된 세그먼트를 올바른 소켓에 전달할 수 있다.
각 세그먼트는 출발지 포트 번호와 목적지 포트 번호를 포함하고 있다. 전송 계층은 이 포트 번호를 확인해 세그먼트를 올바른 소켓으로 전달하고, 소켓을 통해 해당 애플리케이션 프로세스에 데이터를 넘긴다. 이 과정이 역다중화이다.
연결형과 비연결형 다중화/역다중화
1. 비연결형 다중화/역다중화(UDP):
• UDP는 비연결형 프로토콜로, 데이터를 전송하기 전에 연결을 설정하지 않는다. UDP 세그먼트는 출발지와 목적지의 포트 번호를 포함하며, 이를 통해 목적지 호스트는 세그먼트를 올바른 소켓으로 전달한다.
• 예를 들어, Host A의 프로세스가 UDP 포트 19157을 사용해 Host B의 UDP 포트 46428로 데이터를 전송한다고 가정해보자. 전송 계층은 이 정보를 세그먼트에 포함해 네트워크 계층으로 넘기고, Host B에서 세그먼트가 수신되면 전송 계층은 포트 번호 46428을 보고 올바른 소켓으로 데이터를 전달한다.
2. 연결형 다중화/역다중화(TCP):
• TCP는 연결형 프로토콜로, 연결을 설정한 후 데이터를 주고받는다. TCP 소켓은 출발지 IP 주소, 출발지 포트 번호, 목적지 IP 주소, 목적지 포트 번호로 식별된다. 즉, 네 가지 정보가 합쳐져 하나의 TCP 연결을 구분하는 것이다.
• 예를 들어, 두 개의 TCP 세그먼트가 같은 목적지 포트 번호를 가지고 있더라도, 출발지 IP 주소나 출발지 포트 번호가 다르면 서로 다른 소켓으로 전달된다.
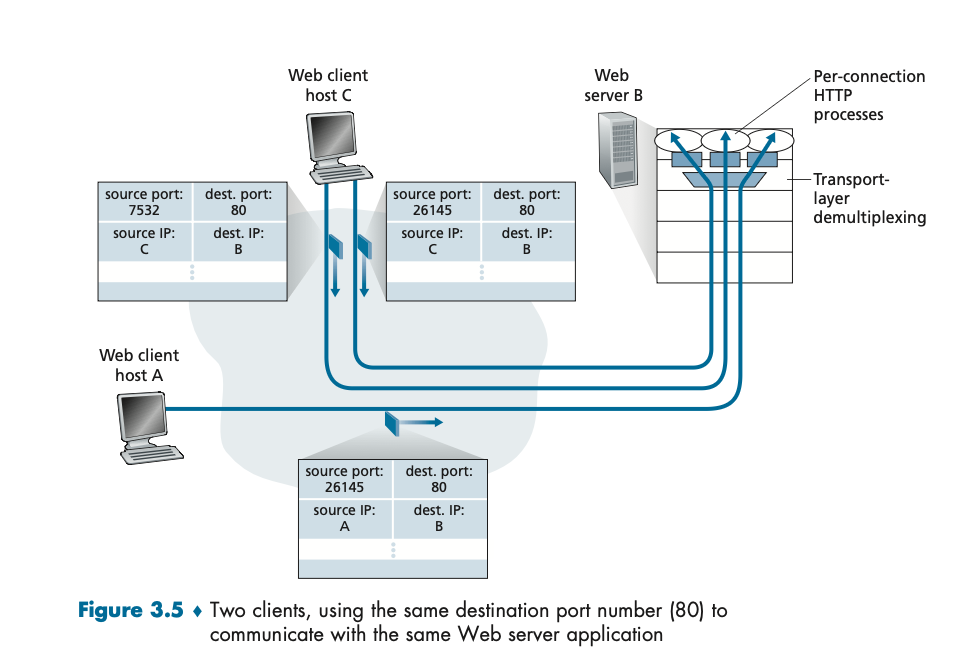
실생활 비유
이 과정은 우편 시스템에 비유할 수 있다. 우편물에는 수신자의 주소와 우편번호가 적혀 있으며, 이 정보는 우편물이 올바른 집으로 배달되는 데 사용된다. 그 후, 집 안에서는 각 우편물이 가족 구성원들에게 배달된다. 이처럼 전송 계층도 네트워크에서 받은 데이터를 각 애플리케이션 프로세스에 전달하는 역할을 한다.
포트 번호와 소켓의 역할
• 포트 번호: 프로세스를 구분하는 식별자이다. 일반적으로 잘 알려진 포트 번호(0~1023번)는 특정 애플리케이션에 예약되어 있다. 예를 들어, HTTP는 포트 번호 80을 사용하고, FTP는 포트 번호 21을 사용한다. 새로운 애플리케이션을 개발할 때는 다른 포트 번호를 할당해야 한다.
• 소켓: 애플리케이션 프로세스가 데이터를 주고받을 수 있는 통로이다. 소켓은 포트 번호로 구분되며, 포트 번호는 세그먼트의 출발지와 목적지 정보를 포함하고 있다. 전송 계층은 이 정보를 보고 올바른 소켓으로 데이터를 전달한다.
결론적으로, 다중화와 역다중화는 전송 계층의 중요한 기능으로, 데이터를 적절한 프로세스에 전달하는 역할을 한다. UDP는 간단한 다중화/역다중화를 제공하는 반면, TCP는 더 복잡한 방식으로 연결을 관리하고 데이터를 정확하게 전달한다 .
3.3 Connectionless Transport: UDP
UDP란 무엇인가?
UDP는 네트워크 계층의 IP 프로토콜 위에서 동작하는 전송 계층 프로토콜로, 데이터 전송 시에 연결을 설정하지 않는 비연결형 프로토콜이다. 이는 TCP와 달리 신뢰성, 흐름 제어, 혼잡 제어 등의 기능을 제공하지 않는다. UDP는 단순히 데이터를 전송하고, 이 데이터가 목적지에 도착했는지 확인하지 않으며, 데이터를 받지 못하면 재전송하지 않는다. UDP는 네트워크 계층과 거의 직접적으로 통신한다고 볼 수 있다.
UDP는 네트워크에서 데이터를 전송할 때 포트 번호를 이용해 데이터를 올바른 애플리케이션에 전달한다. UDP 세그먼트는 출발지 포트 번호와 목적지 포트 번호, 그리고 간단한 오류 검사를 위한 필드 두 개를 추가한 후, 이를 네트워크 계층(IP)으로 넘긴다. 네트워크 계층은 이 데이터를 최선의 노력(best effort)으로 목적지까지 전송한다.'
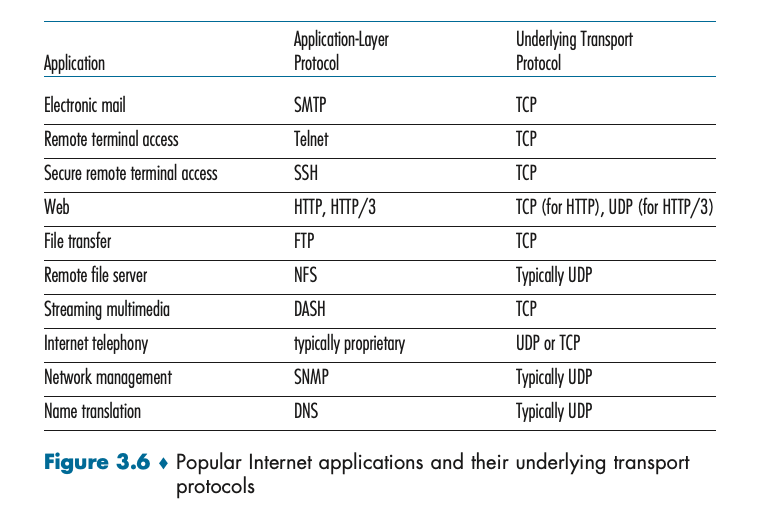
UDP의 특징
1. 다중화/역다중화 기능: UDP는 출발지와 목적지 포트 번호를 이용해 데이터가 올바른 프로세스에 전달되도록 한다. UDP의 역할 중 하나는 바로 이 다중화와 역다중화를 제공하는 것이다. 송신 측에서는 데이터를 포트 번호에 따라 세그먼트로 묶어 네트워크로 전달하고, 수신 측에서는 이 세그먼트를 올바른 포트로 전달해 애플리케이션이 데이터를 처리할 수 있게 한다.
2. 연결 설정 없음: TCP와 달리 UDP는 데이터를 전송하기 전에 연결을 설정할 필요가 없다. 데이터를 바로 전송하며, 중간에 아무런 확인 절차 없이 데이터를 목적지로 보낸다. 이러한 비연결성 덕분에 UDP는 매우 빠르게 데이터를 전송할 수 있다.
3. 신뢰성 없음: UDP는 데이터가 목적지에 도착하는지 확인하지 않으며, 데이터가 손실되더라도 재전송하지 않는다. 따라서 신뢰성이 없는 전송 방법이라고 할 수 있다. 이 때문에 UDP는 손실이 큰 문제로 작용하지 않는 애플리케이션에서 주로 사용된다.
4. 헤더 크기가 작음: TCP 세그먼트는 20바이트의 헤더를 가지지만, UDP 세그먼트는 8바이트의 헤더만을 사용한다. 이는 네트워크 자원을 적게 소비하고, 데이터를 빠르게 전송할 수 있게 한다.
왜 UDP를 사용하는가?
UDP는 신뢰성이 없기 때문에 TCP보다 덜 선호될 것이라고 생각할 수 있지만, 몇 가지 이유로 인해 특정 애플리케이션에서는 UDP가 더 적합하다.
1. 애플리케이션 수준에서의 전송 제어: UDP는 애플리케이션이 데이터를 보낸 즉시 네트워크 계층으로 넘긴다. 반면 TCP는 혼잡 제어나 흐름 제어를 통해 전송 속도를 조절하므로, 데이터가 바로 전송되지 않을 수 있다. 실시간 애플리케이션(예: 인터넷 전화, 실시간 스트리밍)은 최소한의 전송 속도를 요구하며, 일부 데이터 손실을 감내할 수 있다. 이 경우 TCP의 신뢰성 있는 전송보다 UDP가 더 적합하다.
2. 빠른 전송: TCP는 데이터를 전송하기 전에 3-way 핸드셰이크라는 절차를 통해 연결을 설정해야 하지만, UDP는 이러한 과정 없이 바로 데이터를 전송할 수 있다. 예를 들어, DNS는 네트워크에서 빠르게 동작해야 하므로, 연결 설정이 필요 없는 UDP를 사용한다.
3. 연결 상태를 유지하지 않음: TCP는 데이터를 주고받을 때 각 연결에 대한 상태 정보를 유지해야 한다. 반면, UDP는 이러한 연결 상태를 관리하지 않기 때문에 더 적은 자원으로 더 많은 클라이언트를 처리할 수 있다. 따라서 서버가 다수의 클라이언트와 통신해야 하는 경우 UDP가 더 효율적일 수 있다.
4. 헤더 오버헤드가 적음: UDP는 TCP보다 훨씬 적은 헤더 정보를 포함하고 있기 때문에 네트워크 자원을 절약할 수 있다. 따라서 빠른 데이터 전송이 필요할 때 UDP가 유리하다.
UDP 사용 사례
• DNS: DNS는 빠른 응답이 필요하며, 데이터 손실이 큰 문제가 되지 않기 때문에 UDP를 사용한다.
• 스트리밍 멀티미디어: 비디오 스트리밍이나 인터넷 전화와 같은 애플리케이션은 약간의 데이터 손실을 감내할 수 있기 때문에 UDP가 사용된다.
• 네트워크 관리(SNMP): 네트워크 관리 프로토콜(SNMP)은 네트워크가 혼잡한 상황에서도 동작해야 하므로, 연결을 설정하지 않고 빠르게 데이터를 전송할 수 있는 UDP를 사용한다.
UDP 세그먼트 구조
UDP 세그먼트는 네 가지 필드로 구성된다:
1. 출발지 포트 번호: 데이터를 보낸 프로세스의 포트 번호.
2. 목적지 포트 번호: 데이터를 받을 프로세스의 포트 번호.
3. 길이 필드: UDP 세그먼트의 전체 길이(헤더와 데이터 포함).
4. 체크섬 필드: 데이터 전송 중 발생할 수 있는 오류를 감지하기 위한 필드. 오류가 발생하면 수신 측에서 해당 세그먼트를 폐기할 수 있다.
UDP는 이러한 단순한 구조를 가지고 있으며, 빠르고 간단하게 데이터를 전송하는 데 최적화되어 있다.
UDP의 오류 검출: 체크섬
UDP는 데이터 전송 중 오류가 발생했는지 확인하기 위해 체크섬을 사용한다. 체크섬은 세그먼트의 모든 16비트 단어를 더한 후, 1의 보수를 취해 생성된다. 수신 측에서 세그먼트를 수신할 때, 체크섬을 다시 계산해 문제가 없으면 데이터가 올바르게 전송된 것으로 간주한다.
이로써 UDP가 무엇인지, 어떻게 작동하는지, 그리고 왜 사용하는지에 대해 설명했다. UDP는 신뢰성은 없지만 빠르고 가벼운 전송 방법으로, 실시간 애플리케이션에서 유용하다 .
3.4 Principles of Reliable Data Transfer
신뢰성 있는 데이터 전송은 네트워크에서 데이터가 손실되거나 손상되지 않도록 보장하는 것을 말한다. 네트워크는 불완전하기 때문에, 데이터가 전송되는 중간에 손실되거나 순서가 뒤바뀔 수 있다. 이 문제를 해결하기 위해 다양한 전송 프로토콜이 개발되었다.
rdt 프로토콜 버전들
rdt1.0: 완벽한 채널에서의 데이터 전송
• 특징: rdt1.0은 데이터 손실이나 손상이 발생하지 않는 완벽한 채널에서의 데이터 전송을 가정한 매우 단순한 프로토콜이다.
• 동작 방식: 송신자는 데이터를 패킷으로 만들어 전송하고, 수신자는 그 패킷을 받아 애플리케이션에 전달한다. 오류나 손실이 발생하지 않기 때문에, 별도의 확인이나 재전송 메커니즘이 필요 없다.
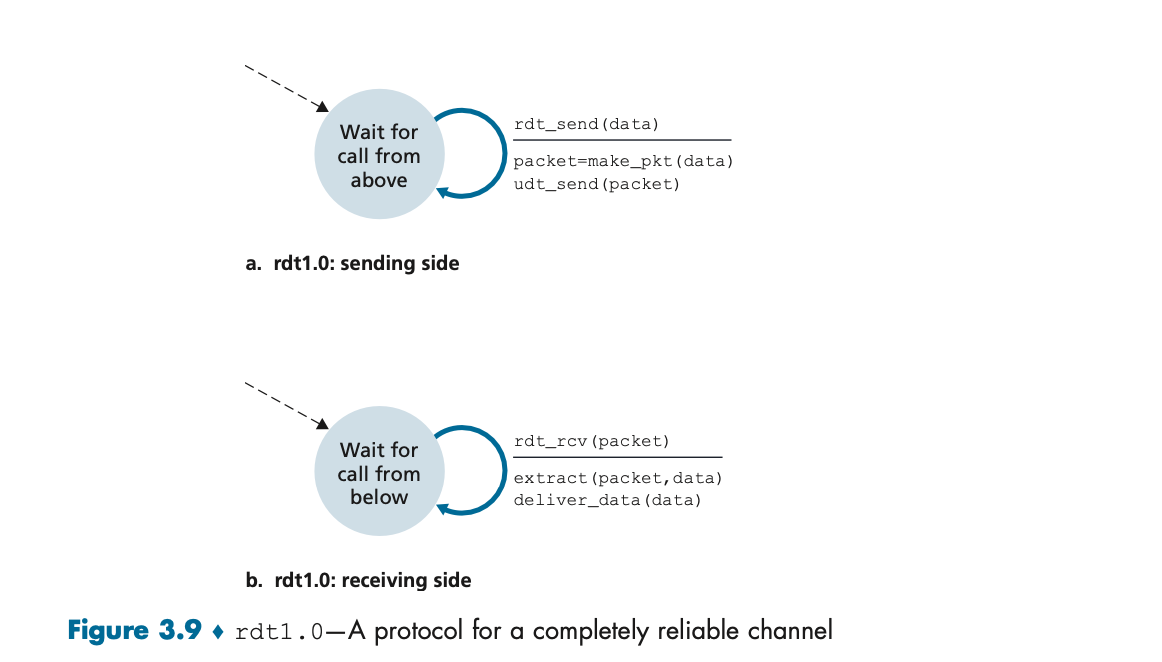
이 그림에서는 rdt1.0의 동작을 보여준다. 송신자와 수신자가 각각 하나의 상태(state)만 가지고 있다. 송신자는 데이터를 받아 패킷으로 만들어 보내고, 수신자는 이를 받아 애플리케이션으로 전달한다. 이 프로토콜에서는 오류가 발생하지 않으므로, 별도의 오류 처리 과정이 필요 없다.
rdt2.0: 오류가 있는 채널에서의 데이터 전송
• 특징: 네트워크에서 비트 오류가 발생할 수 있는 현실적인 상황을 고려한 프로토콜이다.
• 오류 감지 및 피드백: 송신자는 패킷을 전송하고, 수신자는 패킷을 받은 후 체크섬을 통해 오류를 감지한다. 오류가 없으면 **긍정적 응답(ACK)**을, 오류가 있으면 **부정적 응답(NAK)**을 보낸다.
• 재전송: 송신자는 NAK를 받으면 해당 데이터를 다시 전송한다.
이 프로토콜은 간단하지만, ACK/NAK가 손실되면 문제가 발생할 수 있다.
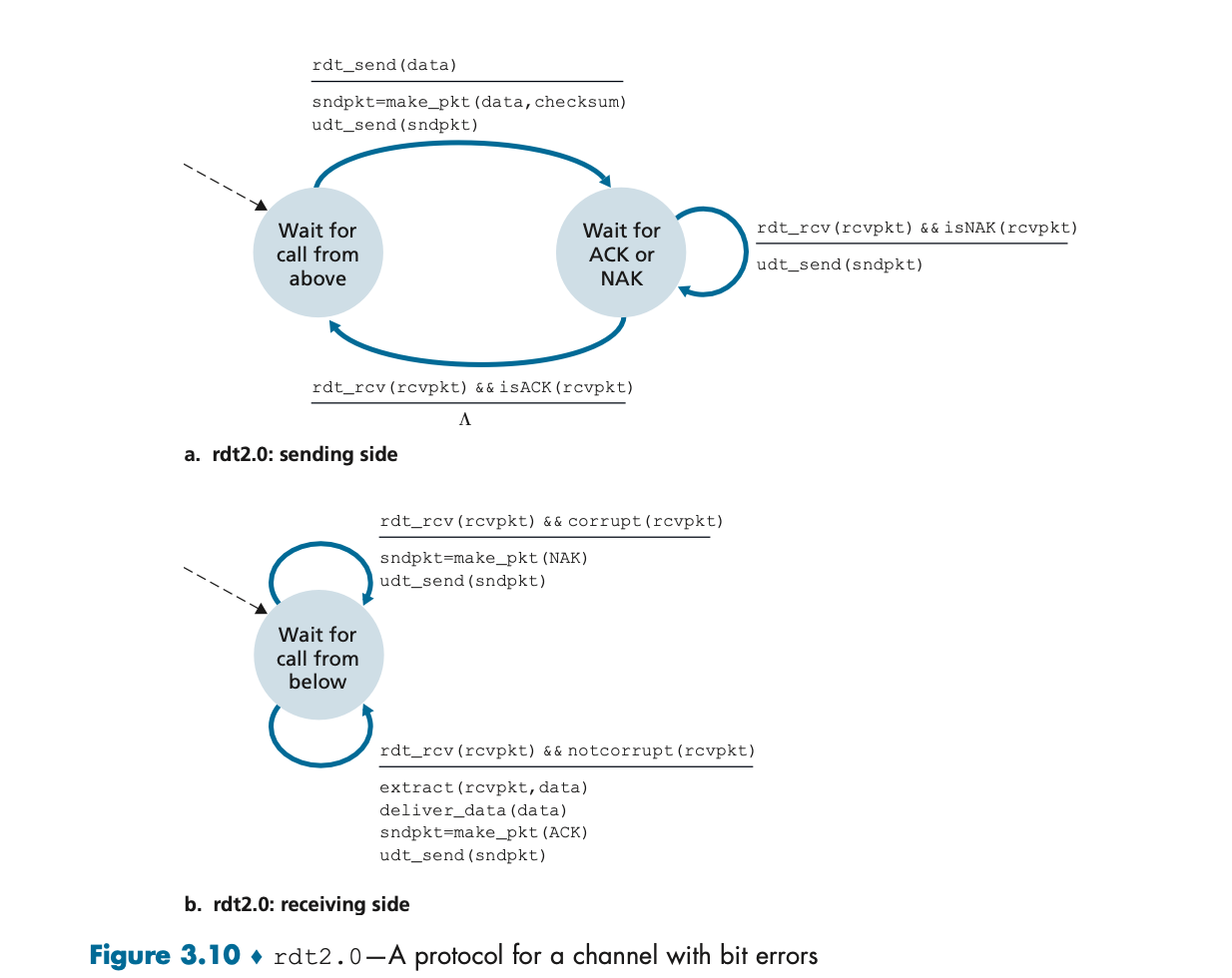
이 그림에서는 rdt2.0 프로토콜이 어떻게 동작하는지를 보여준다. 송신자는 데이터를 보내고, 수신자는 이를 받아 체크섬으로 오류를 감지한다. 만약 오류가 없으면 ACK를 보내고, 오류가 있으면 NAK를 보낸다. 송신자는 NAK를 받으면 패킷을 다시 전송한다. 이 과정은 “멈추고-기다리기(Stop-and-Wait)” 방식이라고 불리며, 하나의 패킷이 올바르게 전달될 때까지 기다렸다가 다음 패킷을 전송한다.
rdt2.1: ACK/NAK 손실 문제 해결
• 특징: rdt2.0의 한계인 ACK/NAK 손실 문제를 해결하기 위해 **순번(sequence number)**을 도입한다.
• 순번: 각 패킷에 순번을 부여함으로써, 수신자는 중복된 패킷을 구별할 수 있게 된다. 이를 통해 중복된 데이터가 수신될 경우 수신자는 ACK만 재전송하고 중복된 데이터를 폐기할 수 있다.
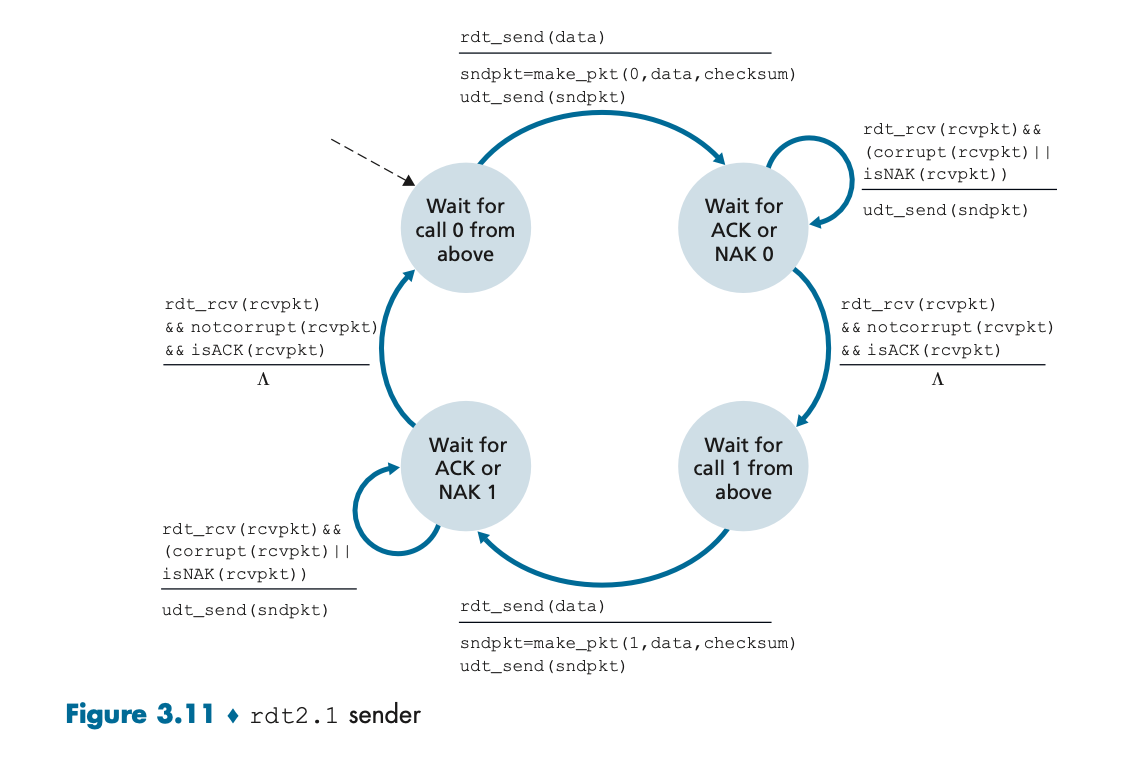
이 그림은 rdt2.1의 송신자 상태 다이어그램이다. rdt2.1 프로토콜은 비트 오류를 처리하기 위해 **순번(sequence number)**을 도입했다. 패킷이 손상되었거나 잘못된 ACK/NAK를 수신한 경우, 송신자는 해당 패킷을 재전송한다.
상태:
1. 송신자는 데이터 전송 상태에 있다가, ACK나 NAK를 기다리는 상태로 전환된다.
2. 송신자가 ACK를 받으면, 다음 패킷을 전송한다.
3. NAK를 받거나, ACK/NAK가 손상된 경우, 해당 패킷을 다시 전송한다.
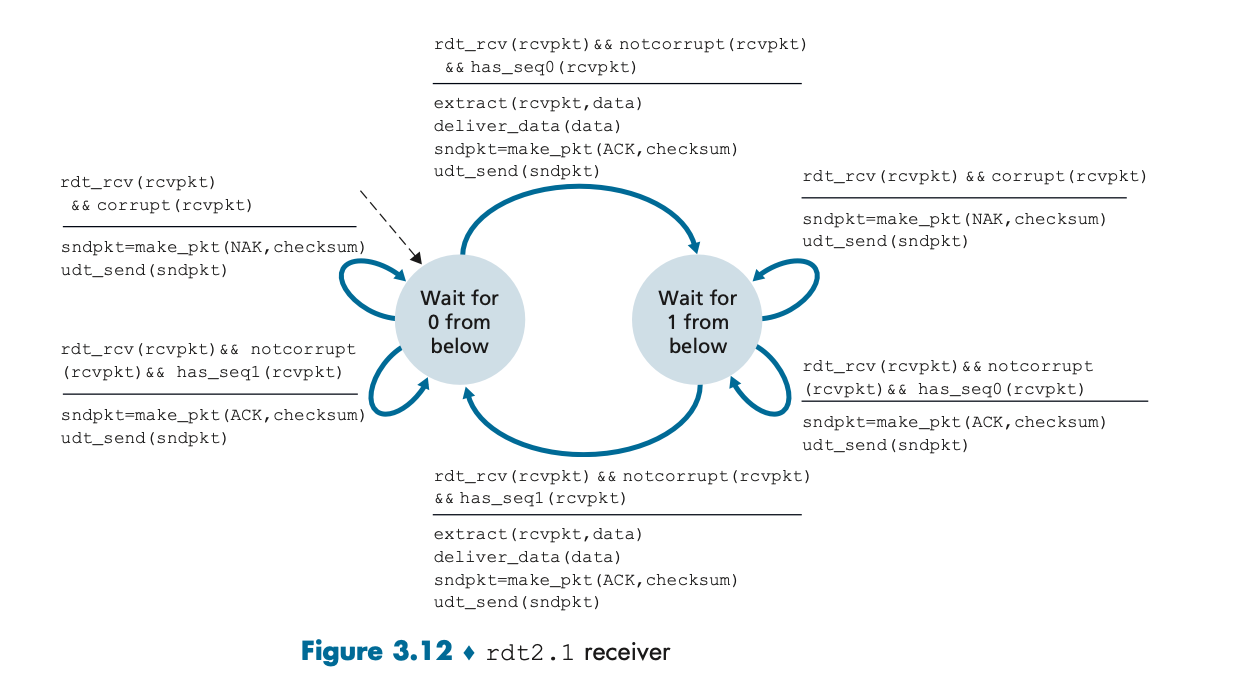
이 그림은 rdt2.1 프로토콜에서 수신자의 상태 다이어그램이다. 수신자는 송신자가 보낸 패킷이 손상되지 않았는지 확인하고, 적절한 ACK 또는 NAK를 송신자에게 보낸다.
상태:
1. 패킷이 순번과 일치하며, 손상이 없는 경우 ACK를 보낸다.
2. 패킷이 손상되었거나 순번이 일치하지 않으면 NAK를 보낸다.
rdt2.2: NAK 없이 ACK만을 사용하는 프로토콜
• 특징: rdt2.1과 마찬가지로 순번을 사용하지만, NAK를 사용하지 않고 ACK만 사용하는 방식이다.
• 동작 방식: 수신자가 손상된 패킷을 받으면, 해당 패킷에 대해 아무 응답도 보내지 않는다. 송신자는 타임아웃이 발생하거나 ACK가 도착하지 않으면, 해당 패킷을 재전송한다.
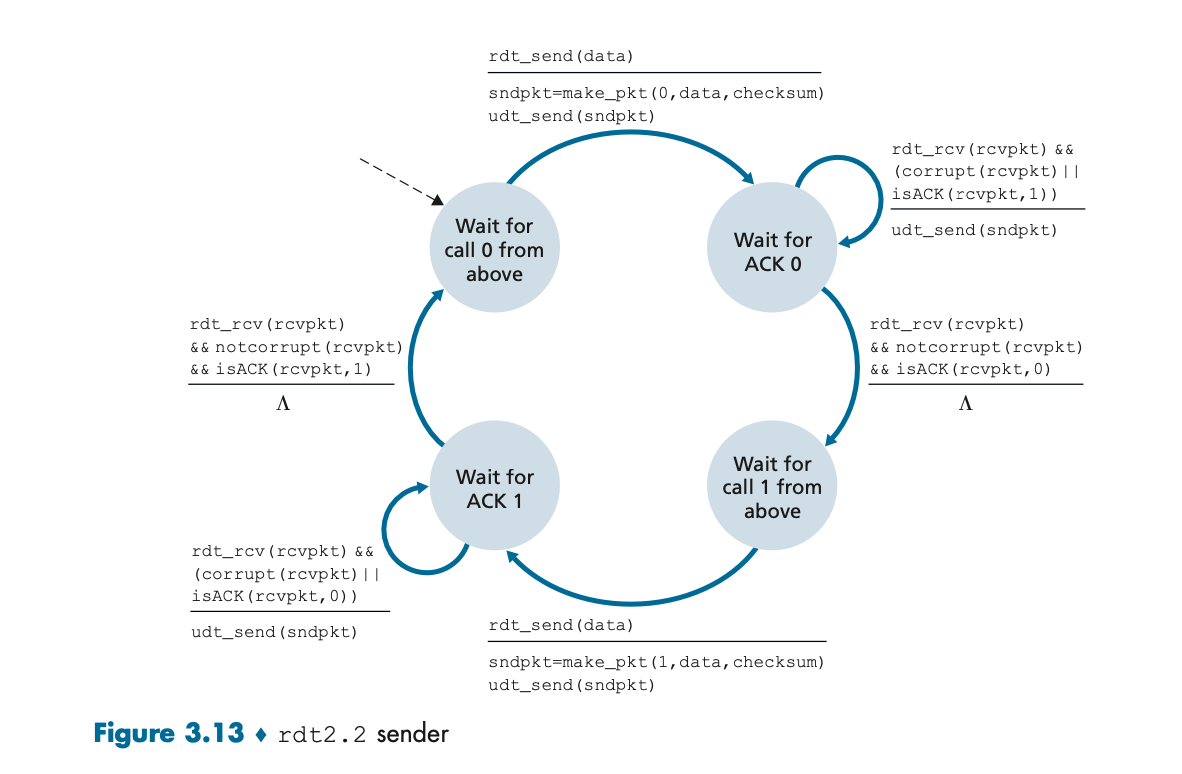
rdt2.2는 NAK 없이 ACK만을 사용하는 프로토콜이다. NAK 대신 송신자는 타임아웃을 기다리고, 일정 시간 동안 ACK가 오지 않으면, 해당 패킷을 재전송한다. 이 그림은 송신자가 어떻게 ACK를 기다리고, 패킷을 재전송하는지 보여준다.
상태:
1. 송신자가 패킷을 전송하고, ACK가 올 때까지 대기한다.
2. ACK가 오면 다음 패킷을 전송하고, ACK가 오지 않으면 해당 패킷을 재전송한다.
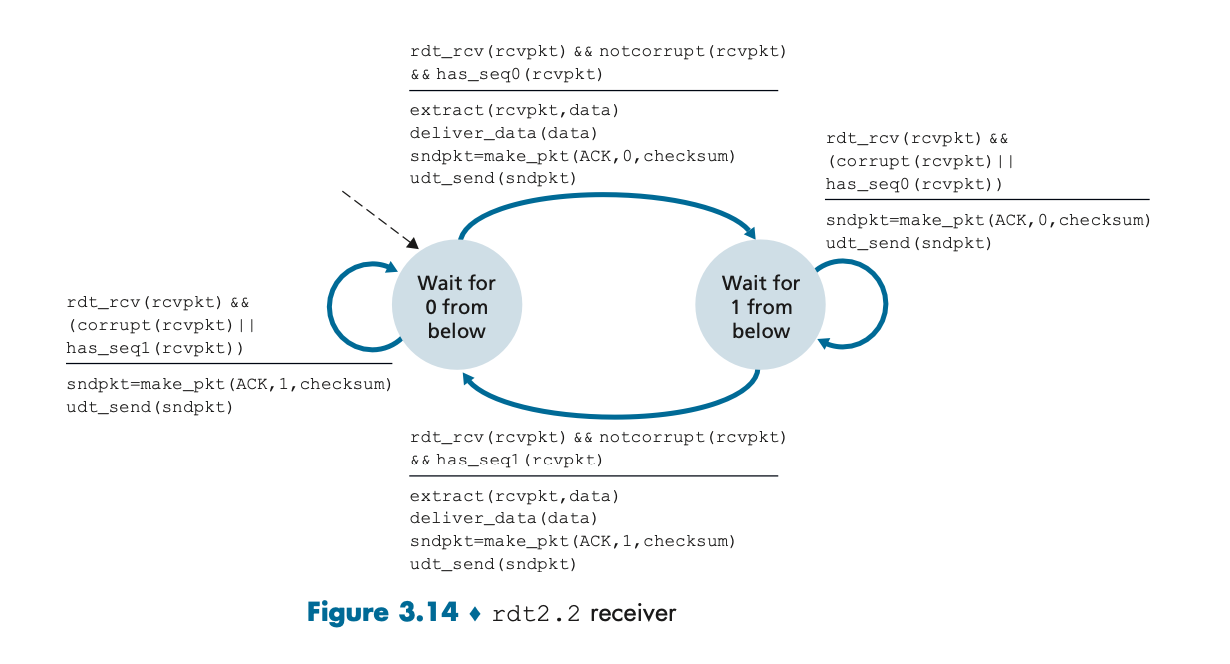
이 그림은 rdt2.2 수신자 다이어그램으로, 수신자는 손상된 패킷을 처리하고 중복된 패킷을 관리하는 방식이 포함되어 있다. 손상되지 않은 패킷에 대해 ACK만 보내는 것이 특징이다.
상태:
1. 패킷이 정상 도착하면, 순번에 맞는 ACK를 송신자에게 보낸다.
2. 중복된 패킷이 도착한 경우에도 ACK만 보낸다.
rdt3.0: 패킷 손실 처리
• 특징: rdt2.2까지는 비트 오류만 처리할 수 있었지만, 패킷 손실 문제를 해결할 수 없었다. rdt3.0에서는 타이머를 도입해 패킷이 손실된 경우 재전송할 수 있는 메커니즘을 추가했다.
• 타이머: 송신자는 패킷을 보낸 후 일정 시간 동안 ACK를 기다린다. 만약 타이머가 만료되면, 송신자는 해당 패킷을 재전송한다.
이 프로토콜은 정지-대기(stop-and-wait) 방식으로 동작한다. 송신자는 하나의 패킷을 전송하고, 그 패킷에 대한 응답(ACK)을 받을 때까지 기다린다.
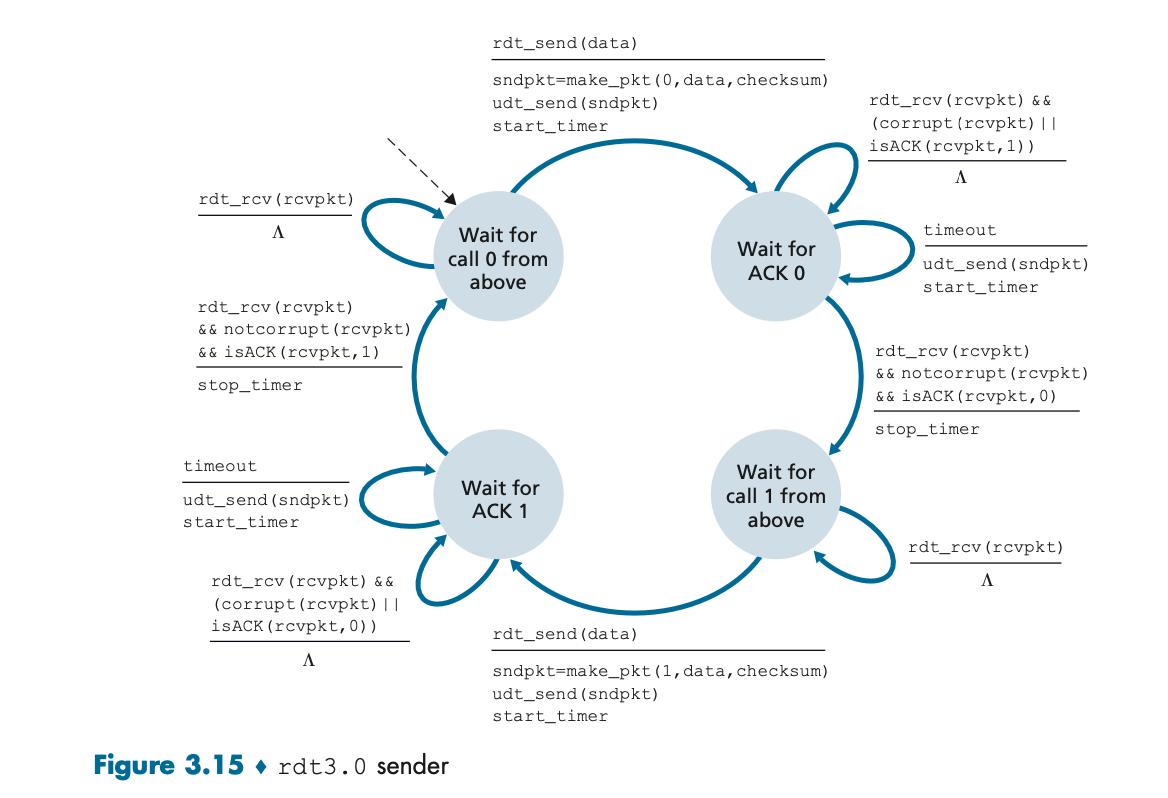
rdt3.0 프로토콜에서는 패킷 손실을 고려해 타이머를 사용한다. 송신자는 타이머를 설정하고, 일정 시간이 지나도 ACK를 받지 못하면 해당 패킷을 재전송한다. rdt3.0은 정지-대기(stop-and-wait) 방식으로 동작한다.
상태:
1. 송신자는 패킷을 전송하고, 타이머를 설정한 후 ACK를 기다린다.
2. ACK가 오면 타이머를 중단하고, 다음 패킷을 전송한다.
3. 타임아웃이 발생하면 해당 패킷을 재전송한다.

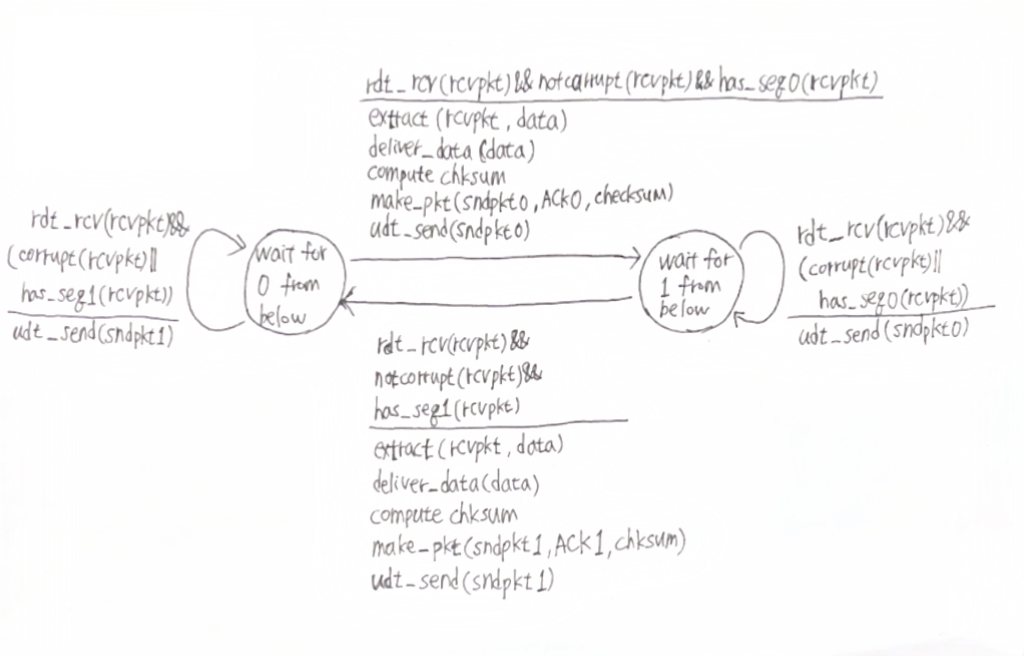

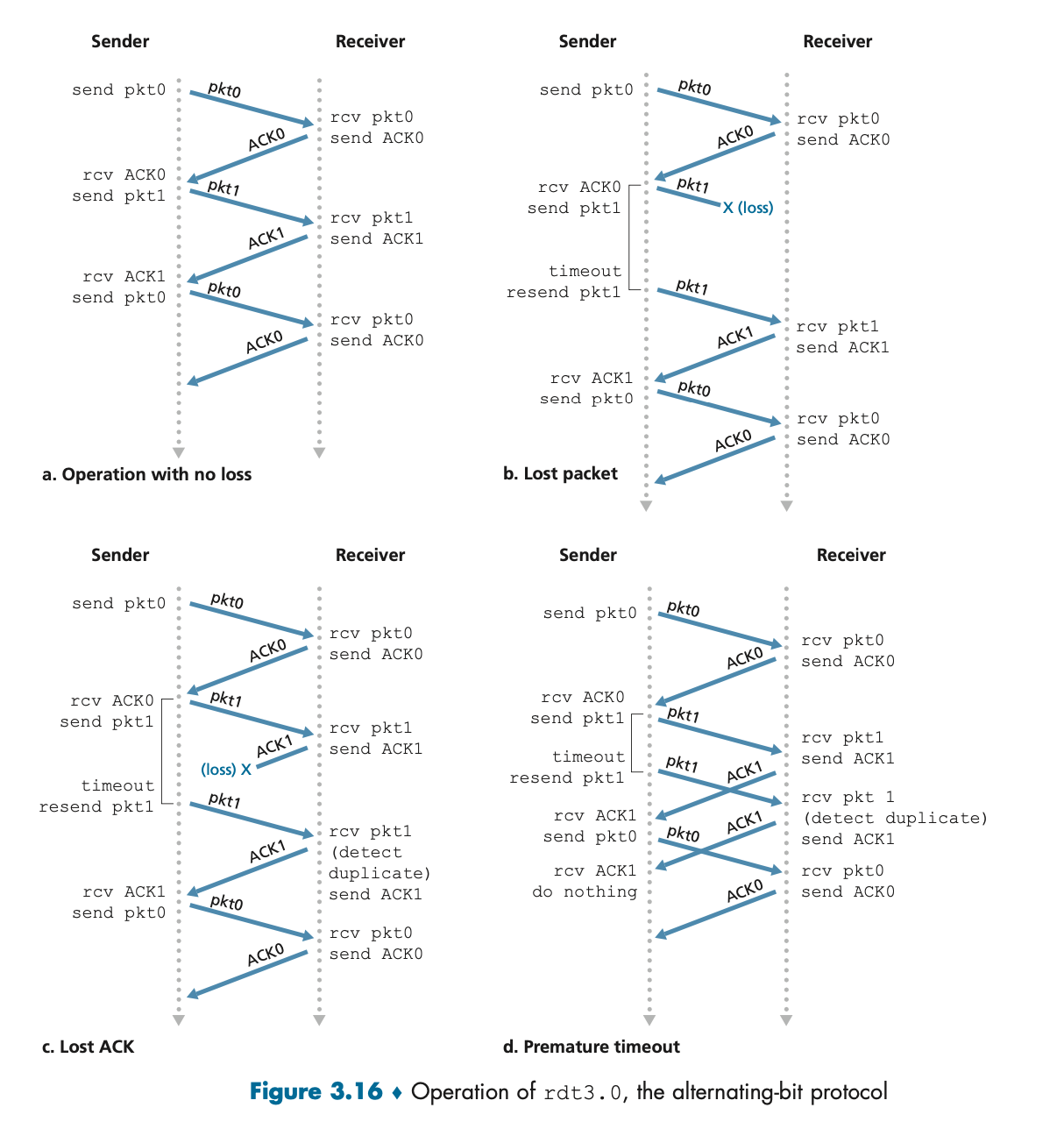
Pipelined 프로토콜
정지-대기 방식의 rdt3.0에서는 패킷 하나를 전송하고, ACK를 기다리는 동안 송신자는 아무것도 할 수 없다. 하지만 이 방식은 비효율적이다. 한 번에 여러 패킷을 전송할 수 있으면 네트워크 자원을 더 효율적으로 사용할 수 있다.
이를 해결하기 위해 Pipelining 개념이 도입되었다. Pipelined 프로토콜에서는 송신자가 여러 패킷을 한꺼번에 전송하고, 수신자는 각 패킷에 대한 ACK를 보낸다. 이를 통해 전송 속도를 높이고 네트워크 자원을 더 효율적으로 사용할 수 있다.
Pipelining의 두 가지 주요 프로토콜:
1. Go-Back-N (GBN)
2. Selective Repeat (SR)
Go-Back-N (GBN)
Go-Back-N은 송신자가 한 번에 여러 패킷을 보내고, 그 패킷들에 대한 응답을 기다리는 방식이다. 하지만 만약 하나의 패킷에 오류가 발생하면, 그 이후에 보낸 모든 패킷을 다시 전송해야 한다.
동작 원리:
1. 송신자는 윈도우(window) 크기만큼 여러 개의 패킷을 전송한다. 예를 들어, 윈도우 크기가 4라면 송신자는 한 번에 4개의 패킷을 전송할 수 있다.
2. 수신자는 각 패킷을 받아 순차적으로 확인한다.
3. 만약 패킷 중 하나에 오류가 발생하거나 손실되면, 그 이후의 모든 패킷이 무시되고, 송신자는 오류가 발생한 패킷부터 다시 전송한다.
그림과 공식 설명:
• 윈도우 크기: 송신자가 한 번에 보낼 수 있는 패킷의 수이다. 이 값이 커지면 네트워크 효율성이 높아지지만, 너무 크면 혼잡이 발생할 수 있다.
• 순번: 각 패킷에는 고유의 **순번(sequence number)**이 부여된다. 수신자는 이 순번을 보고 데이터가 올바르게 도착했는지 판단한다.
GBN 프로토콜의 한계는 하나의 패킷에 문제가 발생하면, 그 이후의 모든 패킷을 다시 전송해야 한다는 점이다. 이로 인해 불필요한 재전송이 발생할 수 있다.
Selective Repeat (SR)
Selective Repeat은 GBN의 단점을 개선한 방식으로, 오류가 발생한 패킷만 다시 전송하는 방식이다. 즉, 모든 패킷을 다시 보내는 것이 아니라, 손실되거나 손상된 패킷만 재전송하기 때문에 전송 효율이 더 높다.
동작 원리:
1. 송신자는 여러 개의 패킷을 전송하고, 각 패킷에 대해 개별적으로 ACK를 기다린다.
2. 수신자는 순서대로 도착하지 않은 패킷을 **버퍼(buffer)**에 저장해두고, 손실되거나 오류가 있는 패킷만 요청한다.
3. 송신자는 수신자로부터 NAK를 받으면, 그 패킷만 다시 전송한다.
그림과 공식 설명:
• 윈도우 크기: GBN과 마찬가지로 윈도우 크기가 설정되며, 이 크기만큼의 패킷을 한 번에 전송할 수 있다.
• 순번: SR에서도 각 패킷에 순번이 부여되며, 수신자는 순번을 통해 어떤 패킷이 손실되었는지 확인한다.
Selective Repeat은 GBN보다 효율적이지만, 구현이 더 복잡하다. 수신자는 도착한 패킷을 버퍼에 저장해두고, 순서가 맞지 않는 경우에도 ACK를 보내는 방식으로 동작한다.
Go-Back-N과 Selective Repeat의 비교
Go-Back-N (GBN) Selective Repeat (SR)
재전송 오류가 발생한 패킷 이후의 모든 패킷을 다시 전송 오류가 발생한 패킷만 다시 전송
윈도우 크기 윈도우 크기만큼 한꺼번에 전송 윈도우 크기만큼 전송하되, 개별 패킷을 ACK 처리
효율성 오류가 발생할 때 불필요한 재전송이 많음 더 효율적이지만 복잡한 구현 필요
GBN은 간단한 구현이지만 비효율적일 수 있고, SR은 구현이 복잡하지만 더 효율적이다.
'Book > COMPUTER NETWORKING A TOP-DOWN-APPROACH' 카테고리의 다른 글
| 3.6 Principles of Congestion Control (0) | 2024.11.24 |
|---|---|
| 3.5 Connection-Oriented Transport: TCP (0) | 2024.11.24 |
| CH2_Application Layer(2.5~2.7) (3) | 2024.10.19 |
| CH2_Application Layer(2.3~2.4) (4) | 2024.10.14 |
| CH2_Application Layer(2.1~2.2) (8) | 2024.10.13 |