1. Memory Hierarchy와 공통 질문
메모리 계층 구조 설계에서 블록 배치 및 검색 방식은 중요한 설계 요소이다. 이를 이해하기 위해 네 가지 질문을 다룬다:
1. Where can a block be placed? (블록 배치)
2. How is a block found? (블록 검색)
3. Which block should be replaced? (블록 교체)
4. What happens on a write? (쓰기 정책)
2. Question 1: Where can a block be placed?
블록 배치 방식:
• Direct Mapped:
• 캐시의 특정 한 위치에만 배치 가능.
• 블록 번호 캐시 블록 개수 사용.
• Set-Associative:
• 여러 개의 위치에 배치 가능.
• -way Set-Associative 캐시는 개의 슬롯을 가진 세트를 사용.
• Fully Associative:
• 캐시의 모든 슬롯에 배치 가능.
• 유연성이 가장 높지만 구현 비용이 큼.
효율성:
• Direct Mapped: 간단하고 빠르지만 Conflict Miss가 많음.
• Set-Associative: 유연성과 성능의 균형 제공.
• Fully Associative: Conflict Miss 없음, 하지만 높은 비용과 지연 발생.

그림 5.34: Miss Rate와 Associativity 관계
• Miss Rate는 Associativity 증가에 따라 감소:
• **One-way (Direct Mapped)**에서 Two-way로 변화 시 가장 큰 감소(20~30%).
• 더 높은 Associativity(4-way, 8-way)에서는 감소율이 작아짐.
3. Question 2: How is a block found?
블록 검색 방법:
• Direct Mapped:
• 인덱스를 사용해 즉시 검색.
• 비교 횟수: 1회.
• Set-Associative:
• 인덱스를 사용한 후, 해당 세트의 모든 슬롯을 검색.
• 비교 횟수: Associativity에 비례.
• Fully Associative:
• 캐시의 모든 엔트리를 검색.
• 비교 횟수: 캐시 크기에 비례.
가상 메모리와 Page Table:
• Page Table은 Fully Associative 구조 사용.
• 이유: Miss Penalty(페이지 폴트 비용)가 매우 높기 때문.
• 정확하고 비용 효율적인 Replacement Algorithm 구현 가능.
4. Question 3: Which block should be replaced?
교체 알고리즘:
1. Random Replacement:
• 후보 블록을 랜덤으로 선택.
• 간단한 하드웨어로 구현 가능.
2. Least Recently Used (LRU):
• 가장 오래 사용되지 않은 블록을 교체.
• 정확한 LRU 구현은 복잡하므로 근사 방식 사용.
LRU의 근사화:
• Pair Tracking:
• 각 쌍에서 오래된 블록 추적.
• n -way Set-Associative에서는 LRU 근사화에 n-1비트 필요.
성능 비교:
• Random Replacement는 LRU보다 1.1배 높은 Miss Rate를 가짐.
• 하지만, 구현 비용이 낮아 일부 시스템에서는 Random 방식 사용.
5. Question 4: What happens on a write?
쓰기 정책:
1. Write-Through:
• 캐시와 하위 메모리 계층에 동시에 데이터 쓰기.
• 장점:
• 구현이 간단하고, 데이터 일관성 유지.
• 단점:
• 쓰기 속도가 느리고, 대역폭 요구량 증가.
2. Write-Back:
• 캐시에만 쓰고, Dirty Bit이 설정된 블록만 하위 계층에 쓰기.
• 장점:
• 쓰기 성능 향상, 불필요한 쓰기 방지.
• 단점:
• 데이터 일관성 보장 필요.
6. The Three Cs Model
Miss 분류:
1. Compulsory Miss:
• 캐시가 비어 있는 상태에서 발생(초기 접근).
2. Capacity Miss:
• 캐시 크기가 작아 데이터를 유지하지 못해 발생.
3. Conflict Miss:
• Direct Mapped 또는 Set-Associative 캐시에서 여러 블록이 같은 위치를 경쟁하여 발생.
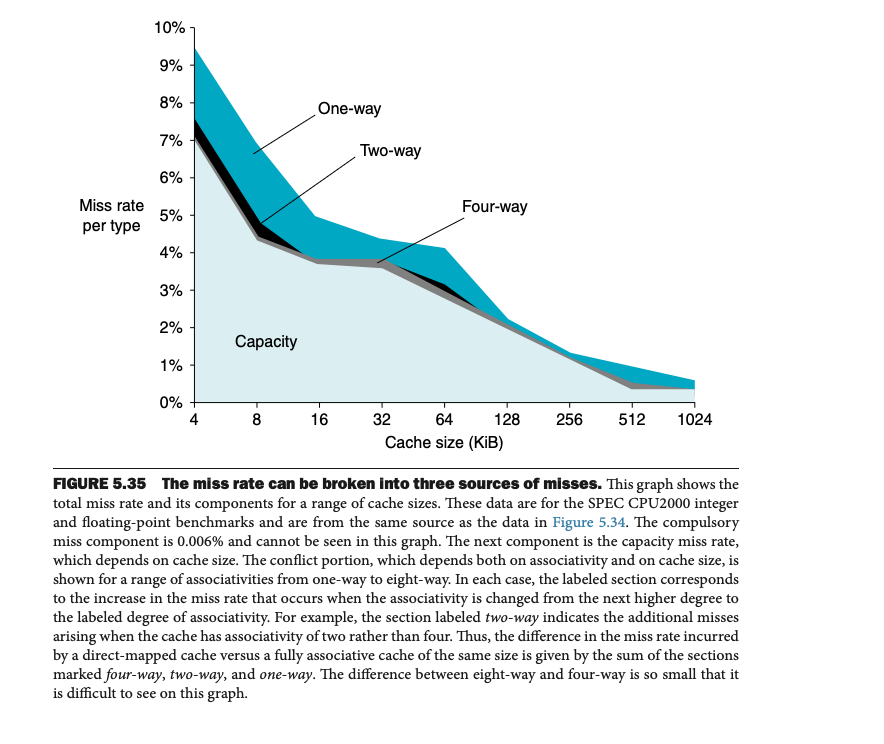
그림 5.35: Miss Rate 구성
• Conflict Miss: Associativity 증가로 감소.
• Capacity Miss: 캐시 크기 증가로 감소.
• Compulsory Miss: 캐시 크기와 독립적, 블록 크기 증가로 감소.
7. 설계 도전과제 (그림 5.36 요약)
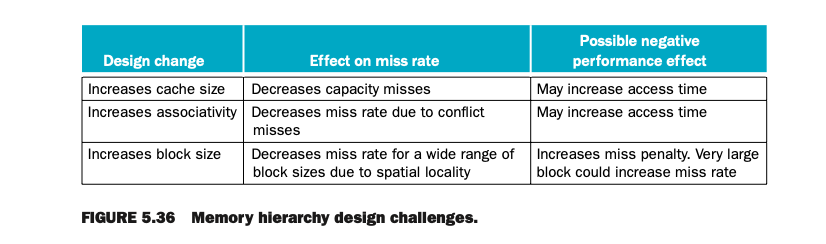
• 캐시 크기 증가:
• Capacity Miss 감소, 그러나 액세스 시간 증가 가능.
• Associativity 증가:
• Conflict Miss 감소, 하지만 액세스 시간 및 비용 증가.
• 블록 크기 증가:
• Compulsory Miss 감소, 그러나 Miss Penalty 증가 가능.
'Book > COMPUTER ORGANIZATION AND DESIGN RISC-V' 카테고리의 다른 글
| 5.10 Parallelism an Memory Hierarchy:Cache Coherence (0) | 2024.12.02 |
|---|---|
| 5.9 Using a Finite-State Machine to Control a Simple cache (0) | 2024.12.02 |
| 5.7 Virtual Memory (2) | 2024.12.02 |
| 5.6 Virtual Machines (0) | 2024.12.02 |
| 5.5 Dependable Memory Hierachy (0) | 2024.12.02 |