
Figure 4.36: 파이프라인 실행을 위한 데이터 경로
• Figure 4.36에서는 파이프라인 실행을 가정하여 각 명령어가 고유의 데이터 경로를 가진다고 설명한다. '각 명령어는 각자의 데이터 경로를 가지며, 공유된 타임라인에 배치되어 서로의 관계를 나타낸다.
• 여기서 중요한 점은 각 명령어의 데이터 경로가 단일 사이클 데이터 경로와 어떻게 연결되는지를 보여주고 있다는 것이다.
각 명령어는 5단계(명령어 인출, 해석, 실행, 메모리 접근, 쓰기-back)로 나뉘어 실행되며,
이들 각각은 고유한 파이프라인 레지스터를 통해 서로 연결된다.
예를 들어:
• 명령어 메모리(IM)는 명령어 인출 단계에서 사용되고, 이후 레지스터 파일(Reg)은 레지스터 읽기 단계에서 사용된다.
• ALU는 실행 단계에서 사용되며, 메모리는 데이터 메모리 접근 단계에서 사용된다. 마지막으로 레지스터 파일은 쓰기-back 단계에서 사용된다.
• 파이프라인 레지스터(예: IF/ID 레지스터)는 각 단계 사이에 데이터를 저장하고 전달하는 역할을 한다. 세탁기 비유로 보면, 각 단계 간 옷을 이동시키는 바구니와 같다. 데이터가 각 단계에서 저장되고 전달되어, 파이프라인 내에서 명령어들이 병렬로 실행될 수 있게 된다.

Figure 4.37: 파이프라인 데이터 경로
• Figure 4.37은 파이프라인 데이터 경로(datapath)를 파이프라인 레지스터와 함께 시각적으로 나타낸다.
각 단계는 파이프라인 레지스터로 구분되며, 각 명령어가 시간에 따라 어떻게 이동하는지를 보여준다.
• 각 단계는 기억장치(IM), 레지스터 파일(Reg), ALU(산술 논리 유닛), 메모리(DM), 그리고 쓰기-back(WB)로 나뉘며, 파이프라인 레지스터는 각 단계를 구분하여 데이터를 전파한다.
• 예를 들어, IF/ID 레지스터는 명령어 인출 단계(IF)와 명령어 해석 단계(ID)를 구분하고, ID/EX 레지스터는 명령어 해석 단계와 실행 단계(EX)를 구분한다.
• 이 그림에서 파이프라인 레지스터는 각 단계 사이에 정보를 저장하고 전파하는 역할을 한다.
예를 들어, IF/ID는 명령어를 레지스터 파일로 전달하며, ID/EX는 레지스터 파일의 데이터를 ALU로 전달하는 역할을 한다.
이러한 레지스터들은 각 단계의 데이터가 올바른 시간에 전달되도록 한다.
• **프로그램 카운터(PC)**는 파이프라인에 중요한 역할을 한다. PC는 명령어 인출 단계에서 사용되며, 각 명령어가 다음 명령어 주소를 계산하는 데 필요하다. PC는 조건부 분기가 있을 때 중요한 역할을 하며, 분기 예측에 의해 제어된다. 예를 들어, 분기 명령어가 있을 때 PC는 분기 주소로 업데이트된다.
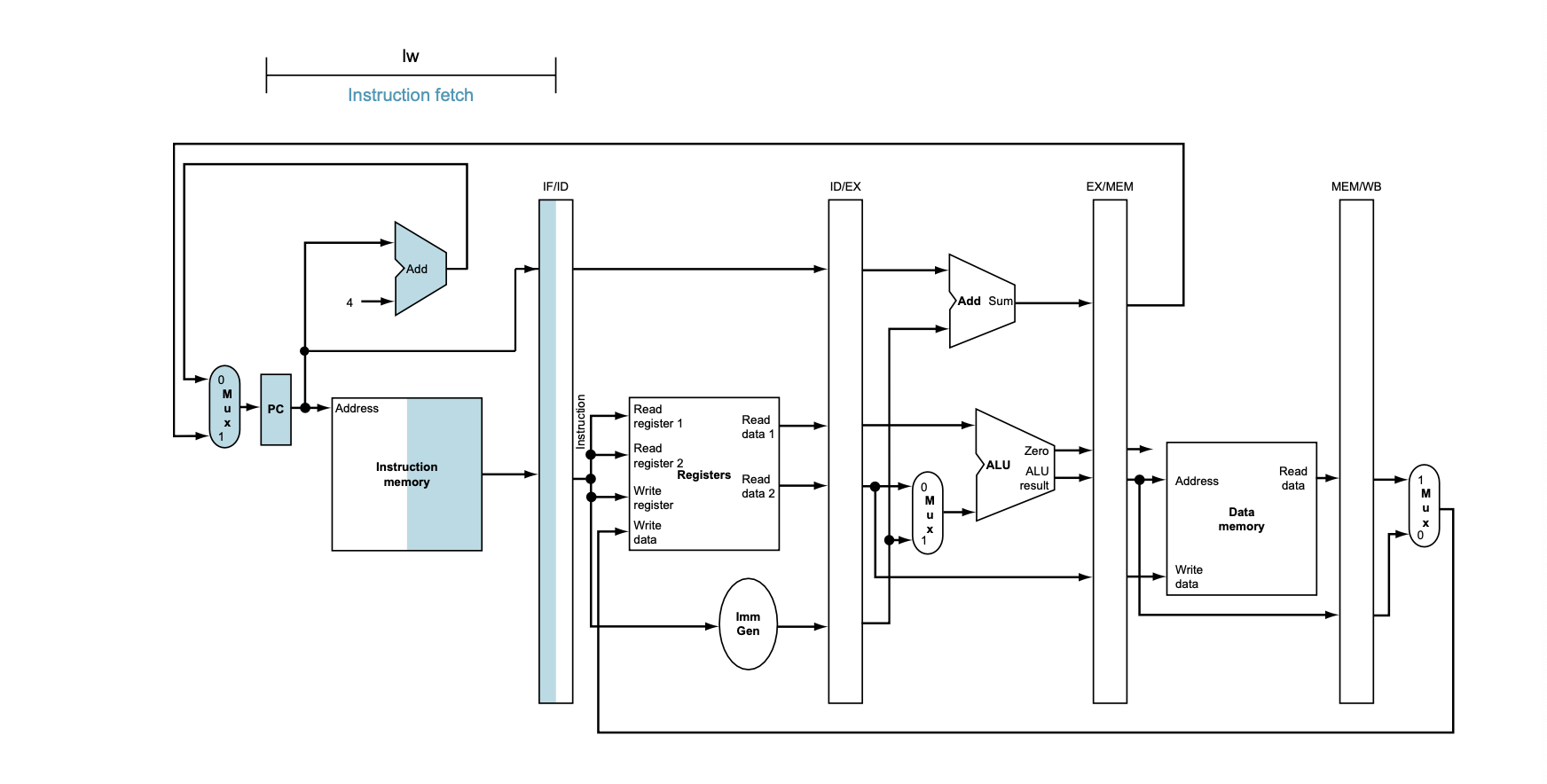
1. 명령어 인출(Instruction Fetch, IF)
• Figure 4.38의 상단에 나타난 명령어 인출 단계에서는, **프로그램 카운터(PC)**가 사용되어 메모리에서 명령어를 읽어온다.
읽은 명령어는 IF/ID 파이프라인 레지스터에 저장된다.
• PC는 매 사이클마다 4만큼 증가한다. 그 후, IF/ID 레지스터에 저장된 명령어는 다음 사이클을 준비하기 위해 다음 단계로 전달된다.
• 이 과정에서 PC 값은 저장되며, 다음 명령어의 주소로 갱신된다. 이때 PC는 분기 명령어와 같은 특정 명령어를 실행할 때 중요하다.
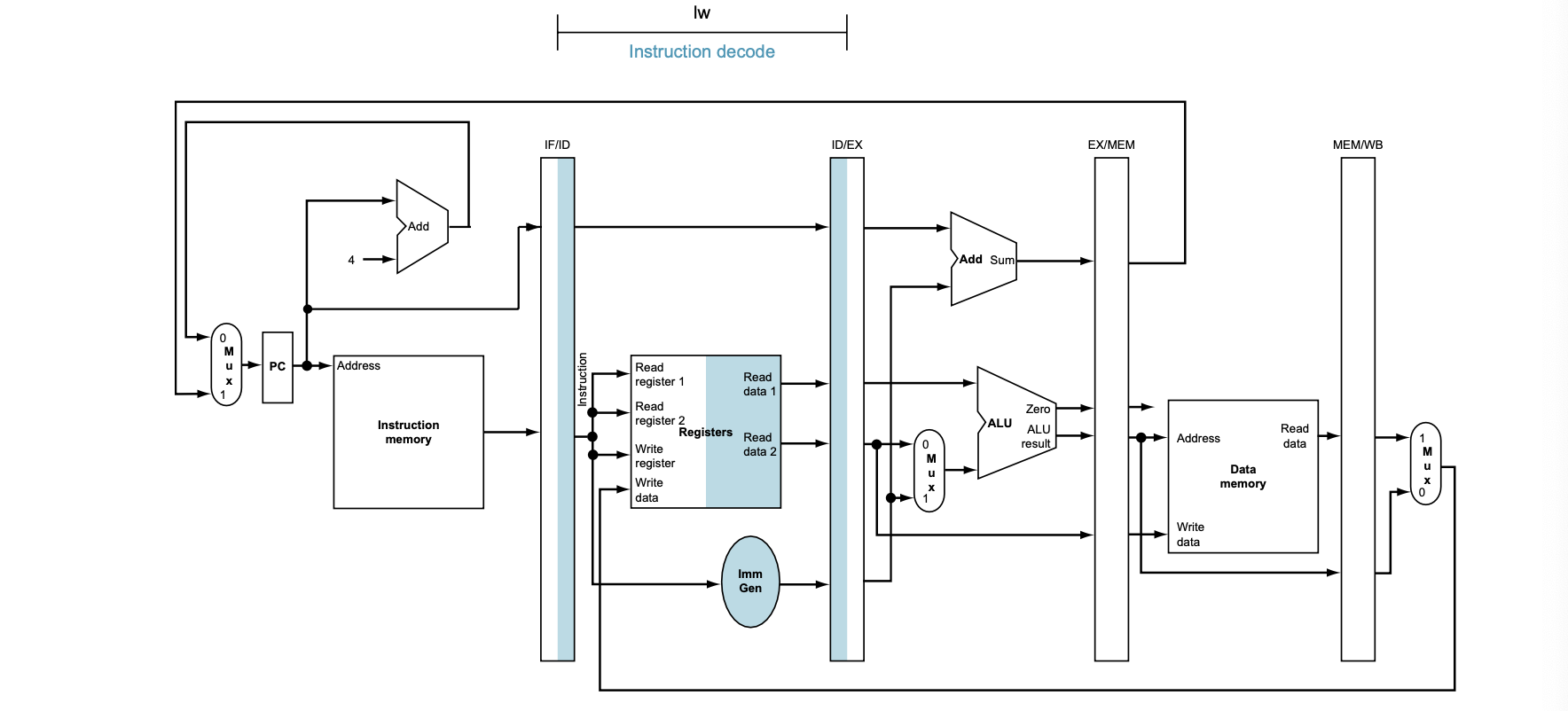
2. 명령어 해석 및 레지스터 파일 읽기(Instruction Decode and Register File Read, ID)
• Figure 4.38의 하단에 표시된 명령어 해석(ID) 단계에서는 명령어가 해석되며, 필요한 레지스터 번호가 IF/ID 레지스터에서 읽혀진다. **즉시값(Immediate value)**도 읽혀져서 64비트로 확장된다.
• 레지스터 파일에서 레지스터를 읽어야 하므로, 해당 레지스터 번호에 맞는 값을 읽어온다. 읽은 값은 ID/EX 파이프라인 레지스터에 저장된다.
• 파이프라인 레지스터는 각 단계 간에 필요한 정보를 저장하고, 다음 단계로 전달하는 역할을 한다. 예를 들어, 레지스터 값이나 PC 주소는 후속 단계에서 필요할 수 있기 때문에 전달된다.

3. 실행 또는 주소 계산(Execute or Address Calculation, EX)
• Figure 4.39에서는 ALU를 사용하여 두 레지스터의 값을 계산하거나 즉시값과 더하는 작업을 한다.
이 단계에서 주소 계산도 이루어진다.
• ALU는 두 레지스터의 값이나 즉시값을 더하여 메모리 접근 주소를 계산한다.
이 계산된 주소는 EX/MEM 파이프라인 레지스터에 저장된다.
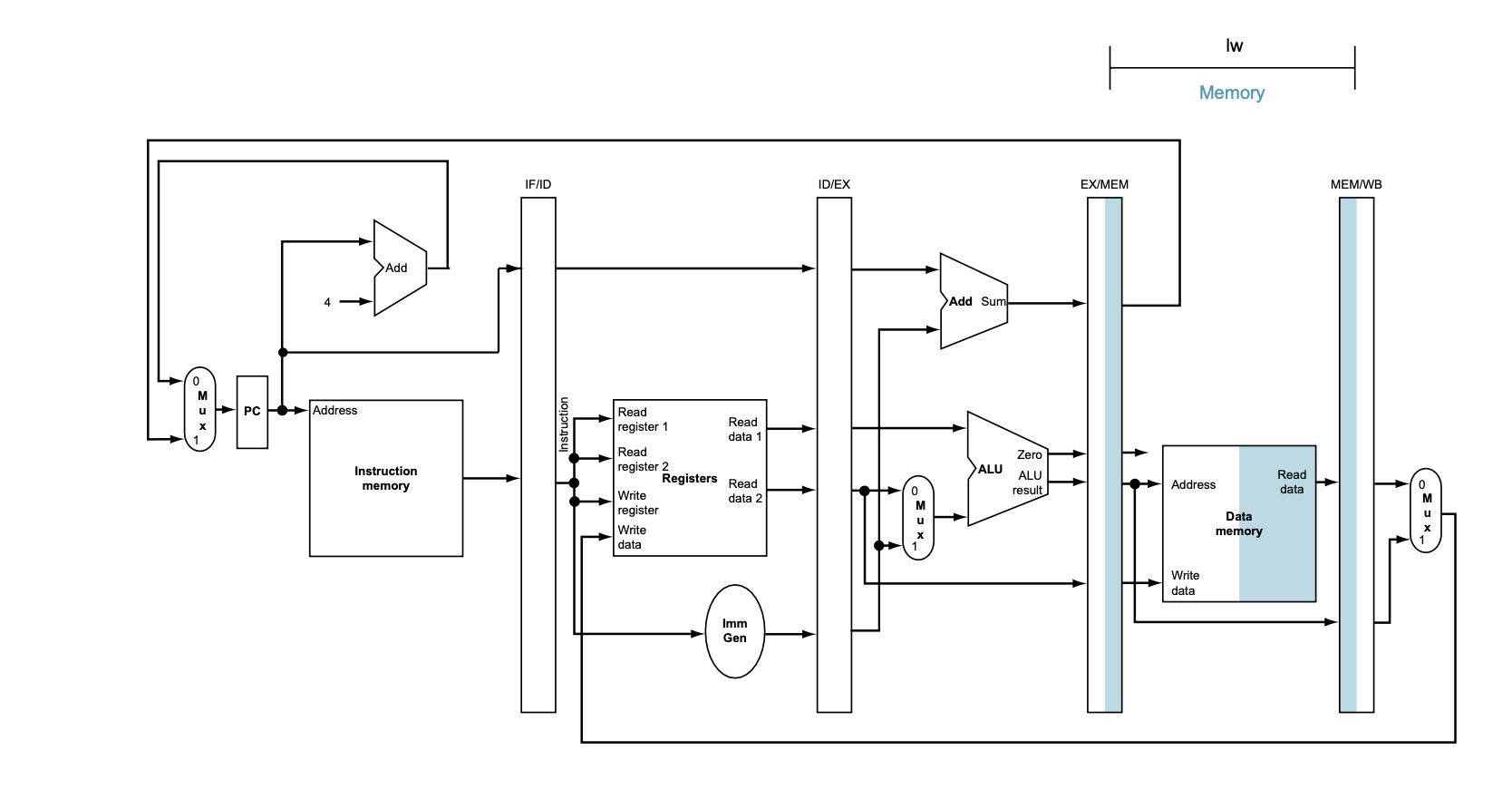
4. 메모리 접근(Memory Access, MEM)
• Figure 4.40에서는 메모리 접근 단계가 표시된다. 이 단계에서는 메모리에서 데이터를 읽거나 메모리에 데이터를 쓴다.
• EX/MEM 파이프라인 레지스터에 저장된 주소를 사용하여, 데이터 메모리에서 값을 읽거나 쓴다.
로드 명령어는 메모리에서 값을 읽고, 저장 명령어는 메모리에 값을 쓴다.
• 이 데이터는 MEM/WB 파이프라인 레지스터에 저장된다.
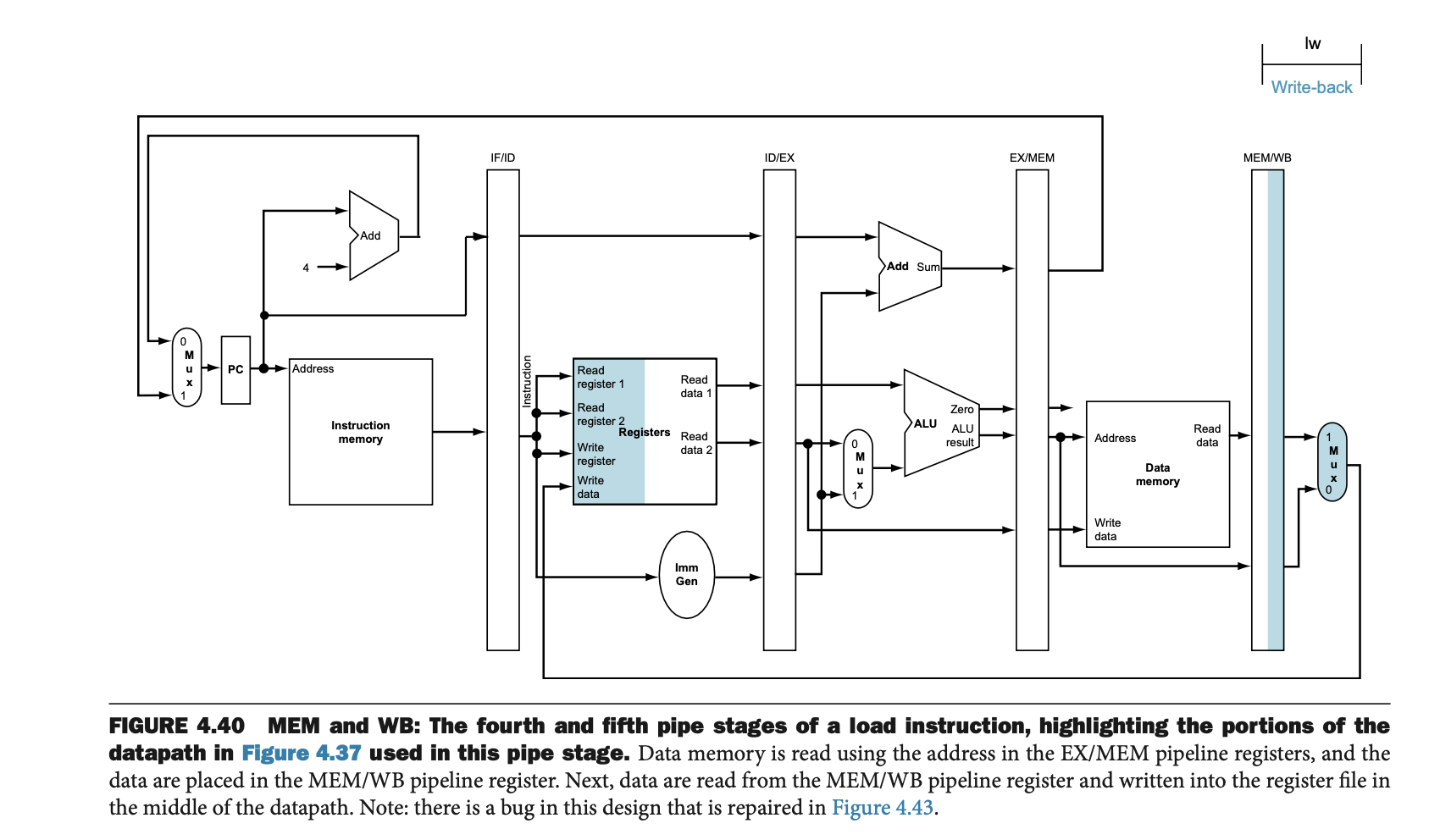
5. 쓰기-back(Write-back, WB)
• Figure 4.40의 하단에 있는 쓰기-back 단계에서는, MEM/WB 파이프라인 레지스터에 저장된 데이터를 레지스터 파일에 다시 저장하는 작업이 이루어진다.
• 이 단계에서는 메모리에서 읽은 값이 레지스터에 기록된다. 저장 명령어는 이 단계를 건너뛰며, 대신 메모리에서 데이터를 읽어 해당 값을 메모리에 기록한다.
로드 명령어 실행 단계 예시
로드 명령어(lw)가 파이프라인을 통해 어떻게 진행되는지 살펴보자.
명령어 인출 (Instruction Fetch)
• PC 주소에서 명령어를 읽고, IF/ID 파이프라인 레지스터에 저장한다. 이 명령어는 lw이다.
명령어 해석 (Instruction Decode)
• lw 명령어에서 레지스터 번호와 즉시값이 해석된다. ID/EX 파이프라인 레지스터에 저장되며, 읽어야 할 레지스터 값과 주소가 계산된다.
실행 (Execute)
• lw 명령어는 ALU에서 주소 계산을 한다. 계산된 주소는 EX/MEM 파이프라인 레지스터에 저장된다.
메모리 접근 (Memory Access)
• lw 명령어는 메모리에서 데이터를 읽는다. 읽은 데이터는 MEM/WB 파이프라인 레지스터에 저장된다.
쓰기-back (Write-back)
• WB 단계에서는 메모리에서 읽은 데이터가 레지스터 파일에 기록된다. 이때 저장 명령어는 쓰기-back을 건너뛰고, 메모리에 데이터를 기록하는 데 집중한다.
저장 명령어 실행 예시
저장 명령어(sw)도 파이프라인을 통해 비슷한 방식으로 처리된다.
명령어 인출 (Instruction Fetch)
• sw 명령어를 PC에서 읽어 IF/ID 파이프라인 레지스터에 저장한다.
명령어 해석 (Instruction Decode)
• sw 명령어에서 레지스터 번호와 즉시값이 해석된다. ID/EX 파이프라인 레지스터에 저장된다.
실행 (Execute)
• sw 명령어는 ALU에서 주소 계산을 하고, 계산된 주소는 EX/MEM 파이프라인 레지스터에 저장된다.
메모리 접근 (Memory Access)
• sw 명령어는 데이터 메모리에 데이터를 쓰기한다. 이 데이터는 MEM/WB 파이프라인 레지스터에 저장된다.
쓰기-back (Write-back)
• sw 명령어는 쓰기-back을 거치지 않는다. 이미 메모리에 데이터를 쓴다.
로드 명령어와 저장 명령어의 공통점
• 두 명령어 모두 다섯 단계를 거친다. 로드 명령어는 메모리에서 데이터를 읽어 레지스터에 저장하는 반면, 저장 명령어는 메모리에 데이터를 기록한다.
• 파이프라인 레지스터는 각 단계에서 데이터를 저장하고 다음 단계로 전달하는 역할을 한다.
버그 수정과 설계 개선
• 로드 명령어에서 목표 레지스터 번호를 IF/ID 레지스터에서 MEM/WB 레지스터로 전달해야 한다는 점에서 문제가 발생할 수 있다. 이를 해결하기 위해 파이프라인 레지스터를 개선하여 목표 레지스터 번호가 각 단계에서 올바르게 전달되도록 한다.
결론
이 설명에서는 로드 명령어와 저장 명령어가 파이프라인에서 어떻게 진행되는지, 파이프라인 레지스터가 어떻게 데이터를 저장하고 전달하는지를 상세히 다뤘다. 파이프라인 설계는 각 명령어가 효율적으로 실행되도록 돕고, 각 명령어의 데이터 전달을 관리하는 중요한 요소다. 파이프라인 레지스터를 통해 데이터를 전달하고, 각 명령어가 독립적으로 병렬 처리될 수 있도록 한다.
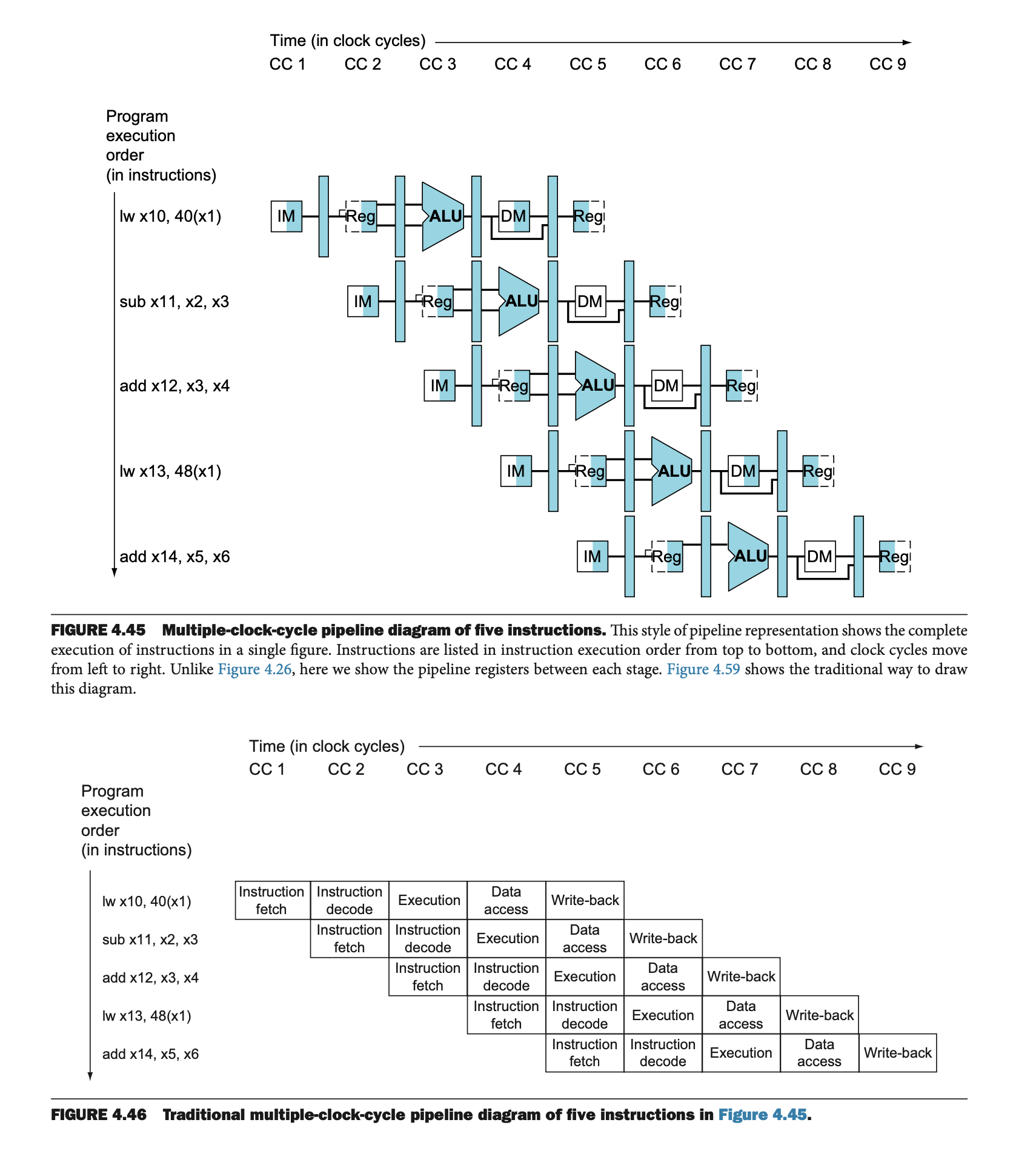
그림 4.45에서는 여러 명령어가 파이프라인을 통해 실행되는 다중 클럭 사이클 파이프라인 다이어그램을 보여준다.
이 다이어그램은 각 명령어가 시간의 흐름에 따라 파이프라인을 통해 어떻게 진행되는지 시각적으로 나타낸다.
각 명령어는 파이프라인의 다섯 단계를 거치며, 각 단계는 하나의 클럭 사이클에 해당한다.
• 그림 4.45는 각 파이프라인 단계에서 명령어가 사용하는 하드웨어 자원을 보여준다.
• 그림 4.46은 전통적인 방식으로 그린 다중 클럭 사이클 파이프라인 다이어그램이다. 이 다이어그램은 각 명령어가 진행하는 단계를 하드웨어 자원을 기준으로 나누어 설명한다.
이 두 다이어그램은 다중 클럭 사이클 방식을 사용하여 명령어 실행 순서를 나타내며, 각 명령어가 어떤 하드웨어 자원을 사용하는지를 보여준다.
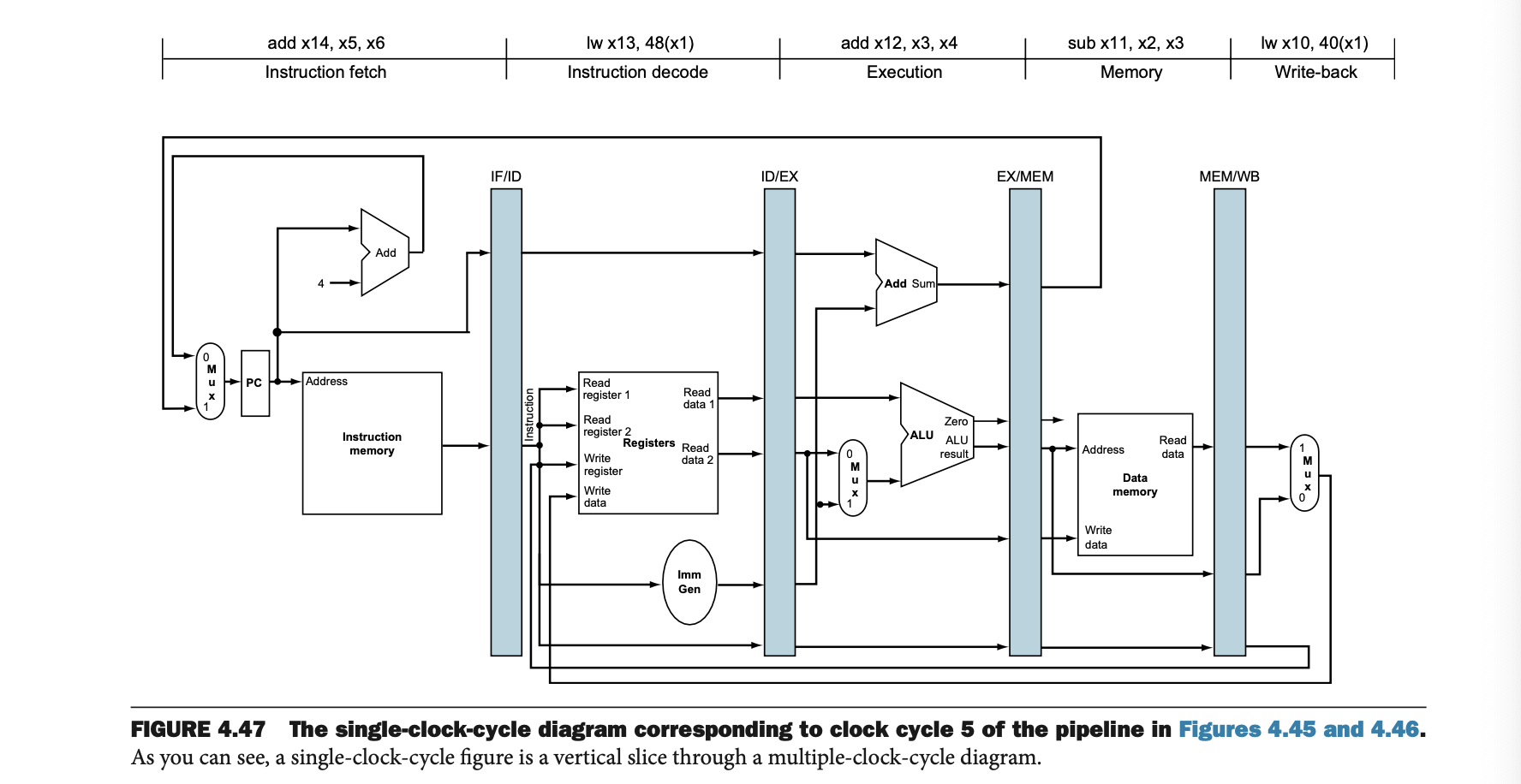
Single-clock-cycle Diagram
그림 4.47에서는 단일 클럭 사이클 다이어그램을 보여주며, 이는 다중 클럭 사이클 다이어그램에서 각 명령어가 실행되는 특정 클럭 사이클을 세로로 잘라낸 형태이다.
이 다이어그램은 각 명령어가 특정 클럭 사이클에 어떤 작업을 수행하는지 세부적으로 나타낸다.
• 그림 4.47은 5번째 클럭 사이클에 대한 정보를 나타내며, 각 명령어가 EX 단계에서 어떤 동작을 수행하는지를 보여준다.
• 단일 클럭 사이클 다이어그램은 각 명령어의 파이프라인 단계를 시간적으로 나누어 보여줌으로써, 각 명령어가 어떤 작업을 수행하는지를 더 자세히 이해할 수 있게 한다.
명령어 순서와 클럭 사이클
이 다이어그램들을 통해 명령어가 파이프라인을 통해 어떻게 실행되는지를 이해할 수 있다.
예를 들어, lw x10, 40(x1) 명령어는 파이프라인의 각 단계를 5개 클럭 사이클에 걸쳐 거친다.
각 명령어는 그 실행에 필요한 자원과 데이터를 각각의 파이프라인 레지스터에 저장하며, 이를 통해 병렬로 처리된다.
'Book > COMPUTER ORGANIZATION AND DESIGN RISC-V' 카테고리의 다른 글
| 4. The Processor (4.9 Control Hazards) (0) | 2024.11.17 |
|---|---|
| 4. The Processor (4.8 Data Hazards:Forwarding versus Stalling) (1) | 2024.11.17 |
| 4. The Processor (4.6. Data Hazard) (1) | 2024.11.15 |
| 4. The Processor (4.6. An Overview of Pipelining) (0) | 2024.11.15 |
| 4. The Processor(4.1~4.5) (1) | 2024.10.10 |