sub x2, x1, x3 // Register x2 written by sub
and x12, x2, x5 // 1st operand (x2) depends on sub
or x13, x6, x2 // 2nd operand (x2) depends on sub
add x14, x2, x2 // 1st(x2) & 2nd(x2) depend on sub
sw x15, 100(x2) // Base (x2) depends on sub
여기서 x2 레지스터는 첫 번째 sub 명령어의 결과로 설정된다.
이후 다른 명령어들이 이 값을 사용하며 데이터 의존성을 발생시킨다.
예를 들어:
•and 명령어는 x2 값을 첫 번째 피연산자로 사용한다.
•or 명령어는 x2 값을 두 번째 피연산자로 사용한다.
•add 명령어는 x2 값을 첫 번째와 두 번째 피연산자로 사용한다.
•sw 명령어는 x2 값을 주소로 사용하여 메모리에 저장한다.
따라서 마지막 네 명령어는 모두 첫 번째 sub 명령어의 결과인 x2에 의존한다.
만약 x2가 처음에는 10이라면, sub 명령어가 실행된 후 x2의 값은 -20이 된다.
그리고 그 후의 명령어들은 모두 -20을 사용해야 한다.
Data Hazard 해결 방법
1. Forwarding (즉시 전달)
• Forwarding은 이전 명령어에서 계산된 결과를 즉시 사용해야 하는 후속 명령어로 전달하는 방법이다.
예를 들어, sub 명령어가 x2에 값을 쓴 후, 그 값은 다음 명령어들에서 바로 사용되어야 하므로, 이를 즉시 전달할 수 있다.
• Forwarding은 파이프라인 지연을 방지하며, 데이터를 빠르게 처리할 수 있도록 도와준다.
2. Stalling (대기)
• Stalling은 데이터가 아직 준비되지 않았을 때, 해당 명령어를 기다리게 하는 방법이다.
즉, 명령어가 다음 단계로 넘어가지 않도록 파이프라인을 멈추는 방식이다.
예를 들어, sub 명령어가 실행되어야 x2 값이 결정되지만, 후속 명령어가 이를 기다리지 않고 실행된다면 잘못된 값을 사용할 수 있다.
이때 Stalling을 사용하여 데이터를 준비할 때까지 후속 명령어들을 멈추게 할 수 있다.

그림 4.53에서는 파이프라인과 관련된 제어 신호들을 연결한 파이프라인 데이터 경로를 보여준다. 이 그림은 데이터가 어떻게 전달되는지, 어떤 단계에서 제어 신호가 활성화되는지를 보여준다.
그림 4.54에서는 다섯 명령어의 파이프라인 의존성을 나타내며, 각 명령어가 서로 의존하고 있는 관계를 시각적으로 표현한다. 이 그림을 통해, 각 명령어가 어떤 레지스터 값을 읽고 쓰는지를 확인할 수 있다.
1. sub- and 의존성:
• sub 명령어가 x2에 값을 쓴 후, and 명령어는 이를 읽어야 한다. 이 경우, Forwarding을 사용하여 x2 값을 즉시 전달할 수 있다.
2. add- and 의존성:
• add 명령어가 x2 값을 두 번 사용하는데, 이 역시 Forwarding으로 해결할 수 있다.
3. sw 의존성:
• sw 명령어는 x2 값을 주소로 사용하는데, 이를 위해 x2가 준비된 후 실행되어야 한다. 이 부분도 Forwarding을 통해 해결 가능하다.
데이터 해저드(Data Hazards)와 포워딩(Forwarding)
데이터 해저드는 하나의 명령이 이전 명령에서 생성된 결과에 의존하는 상황에서 발생한다.
파이프라인 처리에서, 이전 명령이 결과를 쓸 때까지 후속 명령이 실행될 수 없으므로 성능이 저하될 수 있다.
파이프라인에서 발생하는 주요 데이터 해저드는 읽기-후-쓰기(RAW, Read-After-Write) 해저드이다.
이는 후속 명령이 이전 명령의 결과를 읽기 전에 그 결과가 파이프라인에 기록되지 않아서 발생하는 문제이다.
포워딩(Forwarding)으로 해저드 해결
포워딩(또는 바이패싱)은 이러한 데이터 해저드를 해결하는 주요 방법이다.
포워딩은 한 명령에서 계산된 결과를 레지스터 파일에 쓰는 대신, 해당 결과를 바로 다음 명령의 실행 단계(EX)로 전달하여 기다릴 필요 없이 데이터를 사용하게 한다. 즉, 후속 명령이 파이프라인에 의해 실행될 때 필요한 데이터를 바로 전달할 수 있도록 경로를 연결합니다.
그림 4.56에서는 포워딩 전과 포워딩 후의 차이를 보여준다:
• 포워딩 전: 명령어는 실행되기 전에 데이터를 기다리기 때문에 스톨(대기) 상태가 발생.
• 포워딩 후: 포워딩을 추가하여, 데이터를 파이프라인의 이전 단계에서 후속 명령어로 바로 전달할 수 있다.
이 방식은 파이프라인에서 발생하는 대기 시간을 줄여준다.

포워딩 제어 신호
그림 4.57에서는 ALU의 포워딩 제어 신호가 어떻게 설정되는지 설명한다.
이 신호들은 ALU가 어느 파이프라인 레지스터에서 데이터를 가져올지를 결정하는 역할을 한다.
ForwardA와 ForwardB 신호는 ALU의 두 입력에 대해, 각각 EX/MEM 또는 MEM/WB 파이프라인 레지스터에서 데이터를 선택할 수 있게 한다.
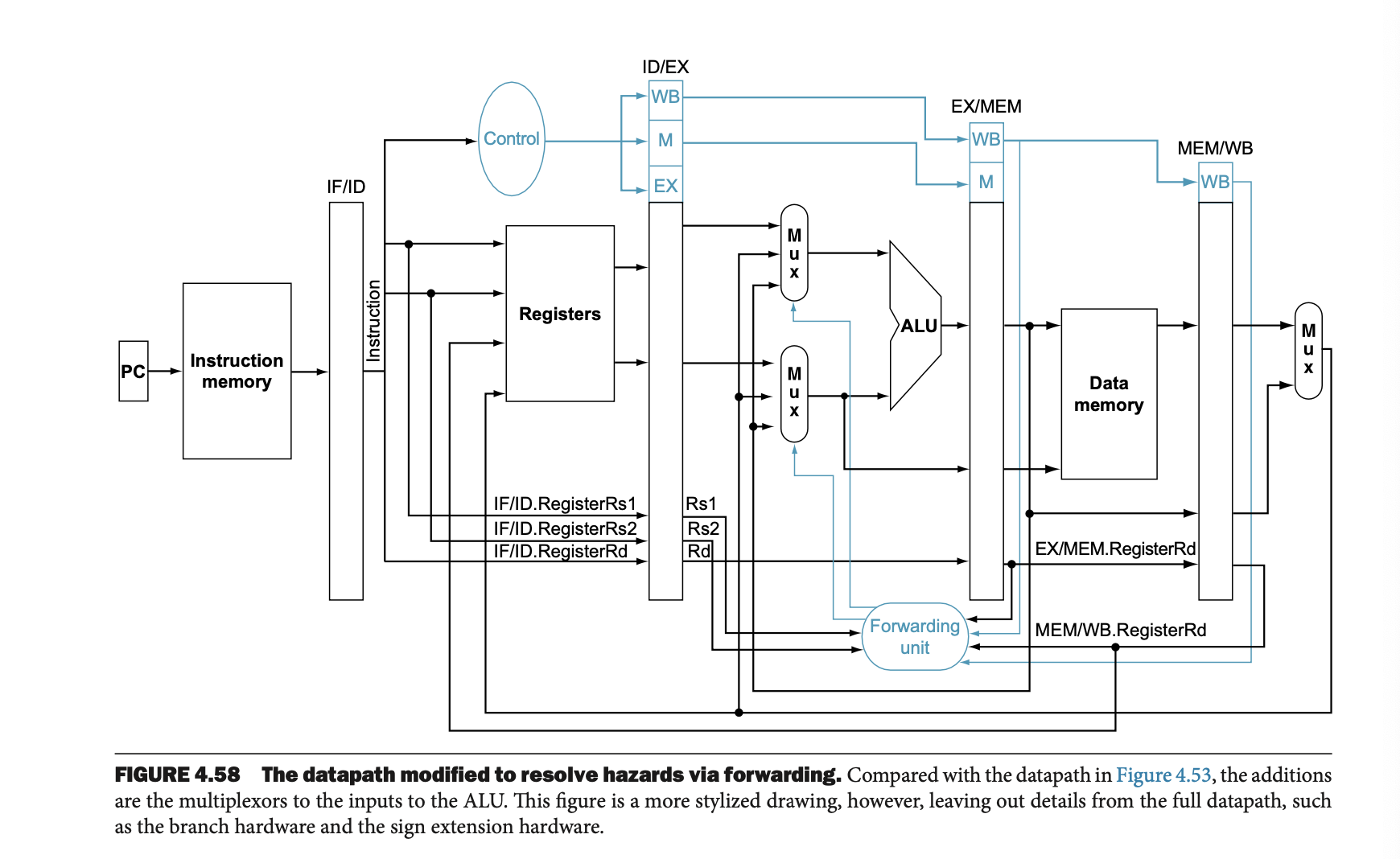
메모리 단계(MEM) 해저드 처리
그림 4.58에서는 MEM 해저드를 해결하기 위한 파이프라인 구조의 수정 사항을 보여준다.
포워딩을 통해, 메모리 단계에서 발생할 수 있는 해저드를 처리한다.
이 수정으로 메모리 접근 후 결과를 즉시 전달할 수 있어, 추가적인 스톨 없이 성능을 최적화할 수 있다.
Data Hazards and Stalls
1. 데이터 해저드와 포워딩
데이터 해저드는 한 명령어가 다른 명령어의 결과를 필요로 하는 상황에서 발생한다.
포워딩은 이 문제를 해결하는 방법 중 하나로, 데이터가 메모리나 레지스터에 저장되기 전에 직접적으로 이전 명령어의 결과를 후속 명령어로 전달한다.
그러나 로드 명령어 뒤에 이어지는 명령어가 그 데이터를 필요로 할 때는 포워딩만으로 해결할 수 없습니다. 이 경우 스톨이 필요합니다.
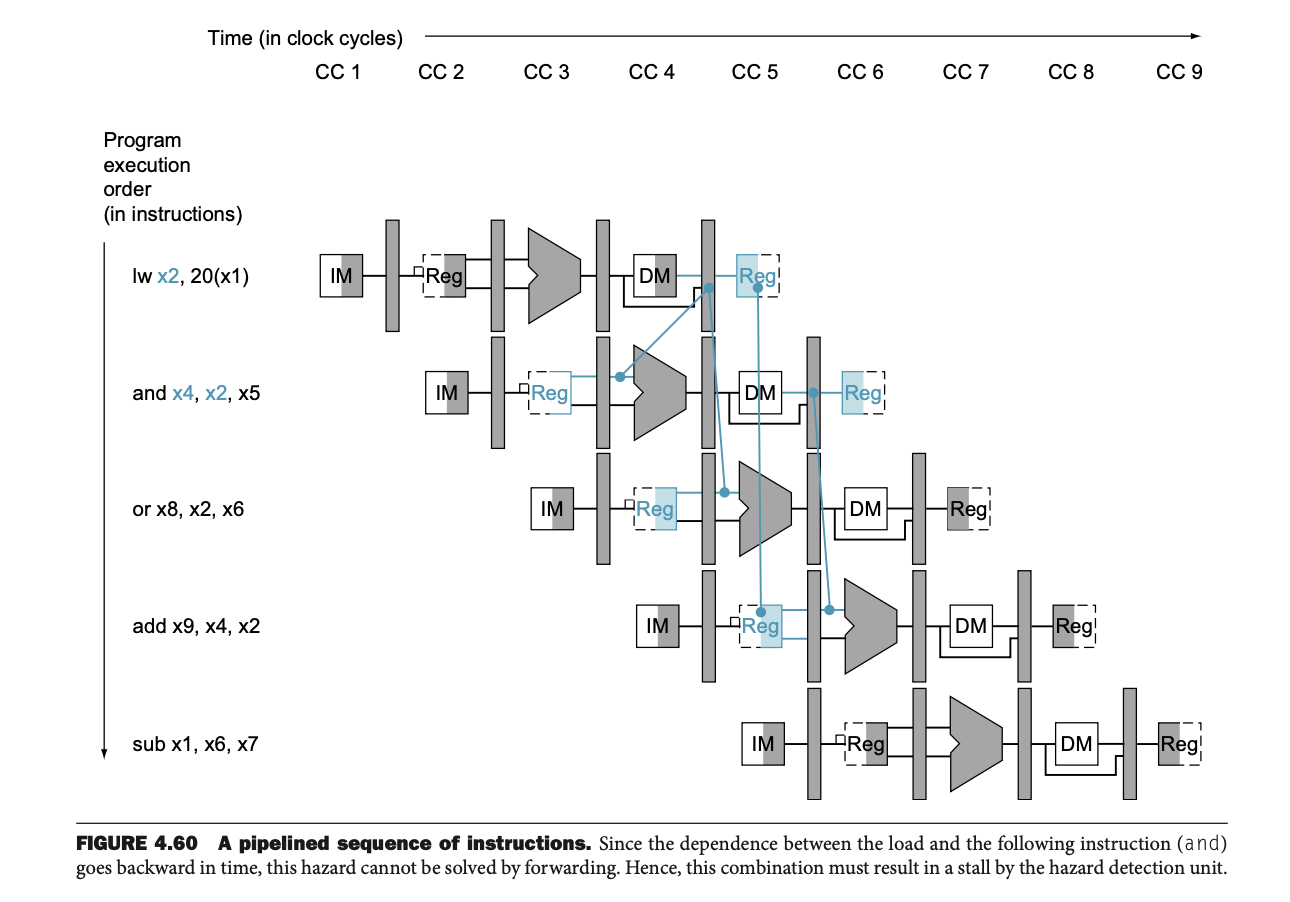
그림 4.60에서는 lw x2, 20(x1) 명령어와 그 뒤에 오는 and x4, x2, x5 명령어 간의 데이터 해저드를 보여준다.
lw 명령어가 메모리에서 데이터를 읽는 동안, and 명령어는 그 데이터를 필요로 한다.
포워딩만으로는 데이터를 바로 전달할 수 없기 때문에, 해저드 검출 장치가 스톨을 삽입하여 파이프라인을 멈추고, 데이터를 안전하게 읽을 수 있도록 한다.
2. 스톨링
스톨링은 파이프라인 내에서 버블을 삽입하여 명령어 실행을 일시적으로 멈추는 방법이다.
스톨링은 주로 데이터 해저드를 처리하는 데 사용되며, 데이터를 올바르게 읽을 수 있도록 기다린다.
이 과정은 명령어가 진행되지 않도록 하여, 데이터가 준비될 때까지 파이프라인을 잠시 멈추게 만든다.
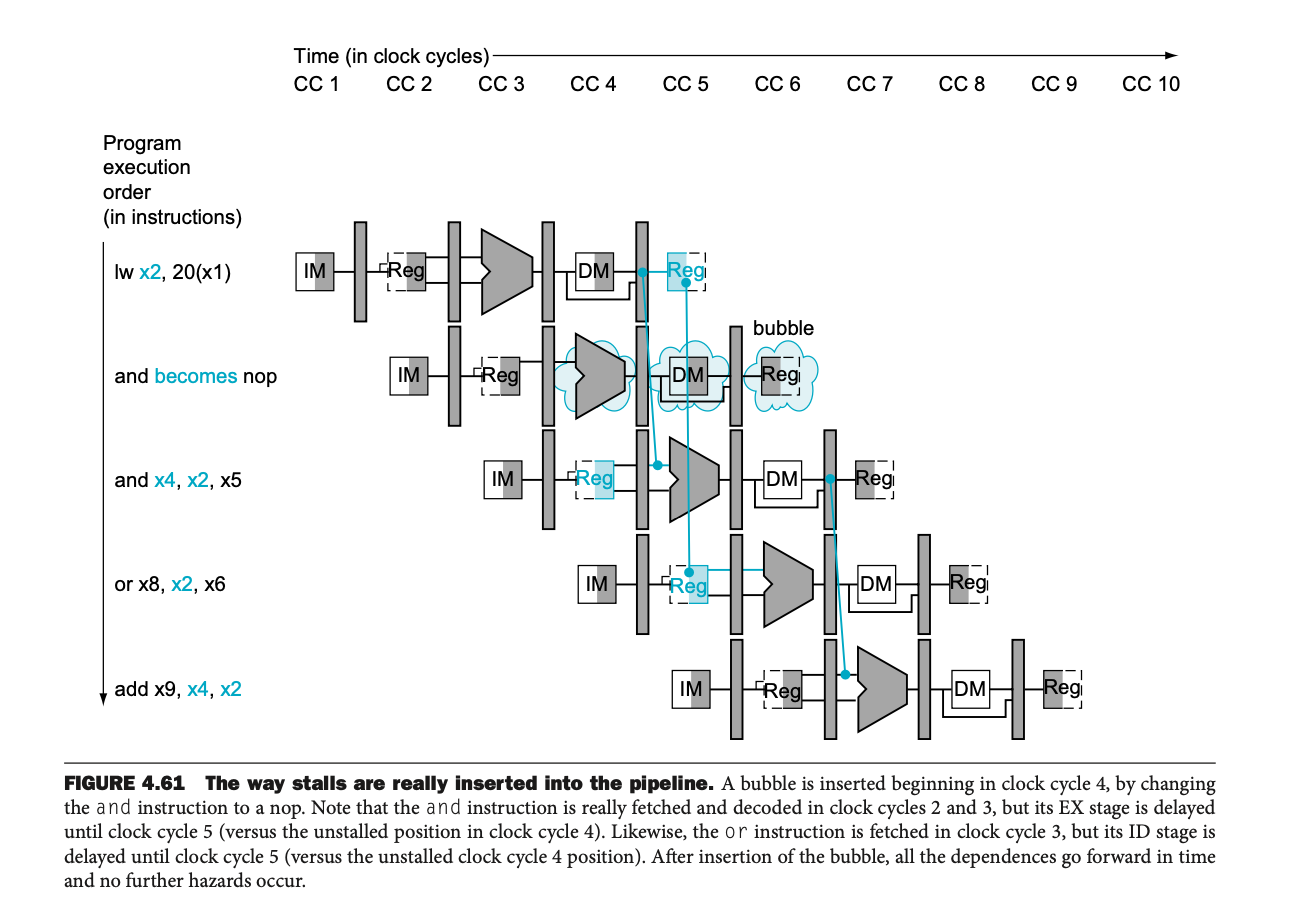
그림 4.61은 스톨링이 파이프라인에 삽입되는 예시를 보여준다.
and 명령어는 버블을 통해 NOP 명령어로 대체되며, 이는 파이프라인에서 아무 작업도 하지 않는 상태로 만들어 데이터가 준비될 때까지 기다리도록 한다.
파이프라인에 삽입된 버블은 후속 명령어들을 한 사이클씩 지연시킨다.
• 버블은 명령어가 실행되지 않고 대기 상태로, 뒤에 있는 명령어들도 함께 지연시킨다.
이는 데이터 해저드를 해결하는 중요한 방법이다.
3. 해저드 검출 장치
해저드 검출 장치는 로드 명령어 뒤에 오는 읽기 명령어에서 발생할 수 있는 데이터 해저드를 감지하여 스톨을 삽입한다.
이를 통해 파이프라인 내에서 데이터가 올바르게 전달되도록 보장한다.
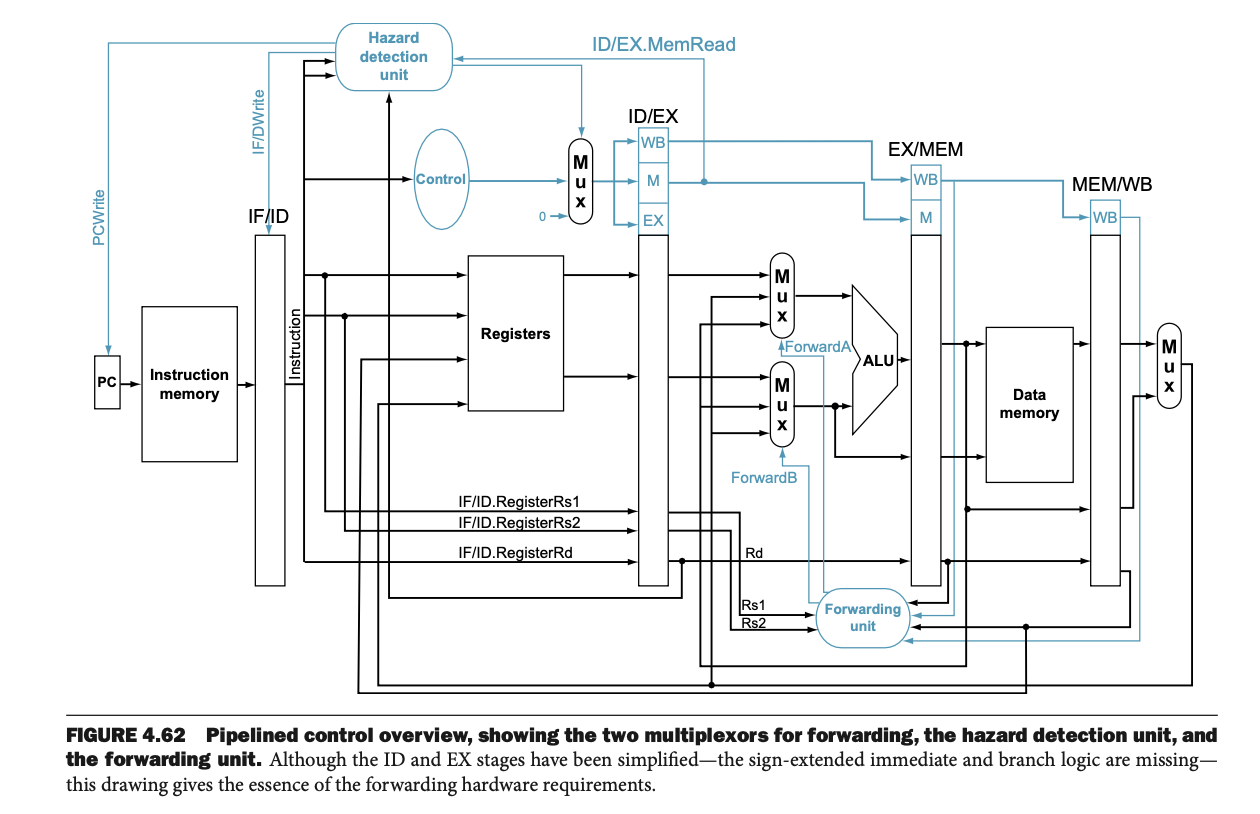
그림 4.62는 해저드 검출 장치와 포워딩 유닛이 어떻게 연결되어 있는지 보여준다.
해저드 검출 장치는 ID/EX.MemRead 신호와 함께 데이터를 읽으려는 명령어가 로드 명령어인지를 확인한다.
만약 로드 명령어가 후속 명령어의 데이터를 준비하는 중이라면, 해저드 검출 장치는 스톨을 삽입하여 후속 명령어가 데이터를 안전하게 읽을 수 있도록 한다.
• 포워딩 유닛은 파이프라인 레지스터에서 데이터를 ALU로 전달하여 빠른 계산이 가능하도록 돕는다.
해저드 검출 장치는 로드 명령어 뒤에 바로 이어지는 명령어가 그 데이터를 사용할 때 스톨을 삽입하여 대기하게 한다.
4. 포워딩 및 해저드 검출 장치
포워딩을 통해 ALU가 바로 계산을 할 수 있도록 하며, 해저드 검출 장치는 로드 명령어 뒤에 오는 명령어가 그 데이터를 읽기 전에 스톨을 삽입한다. 포워딩 유닛은 ALU의 입력을 선택하는 멀티플렉서를 사용하여 데이터를 빠르게 전달한다.
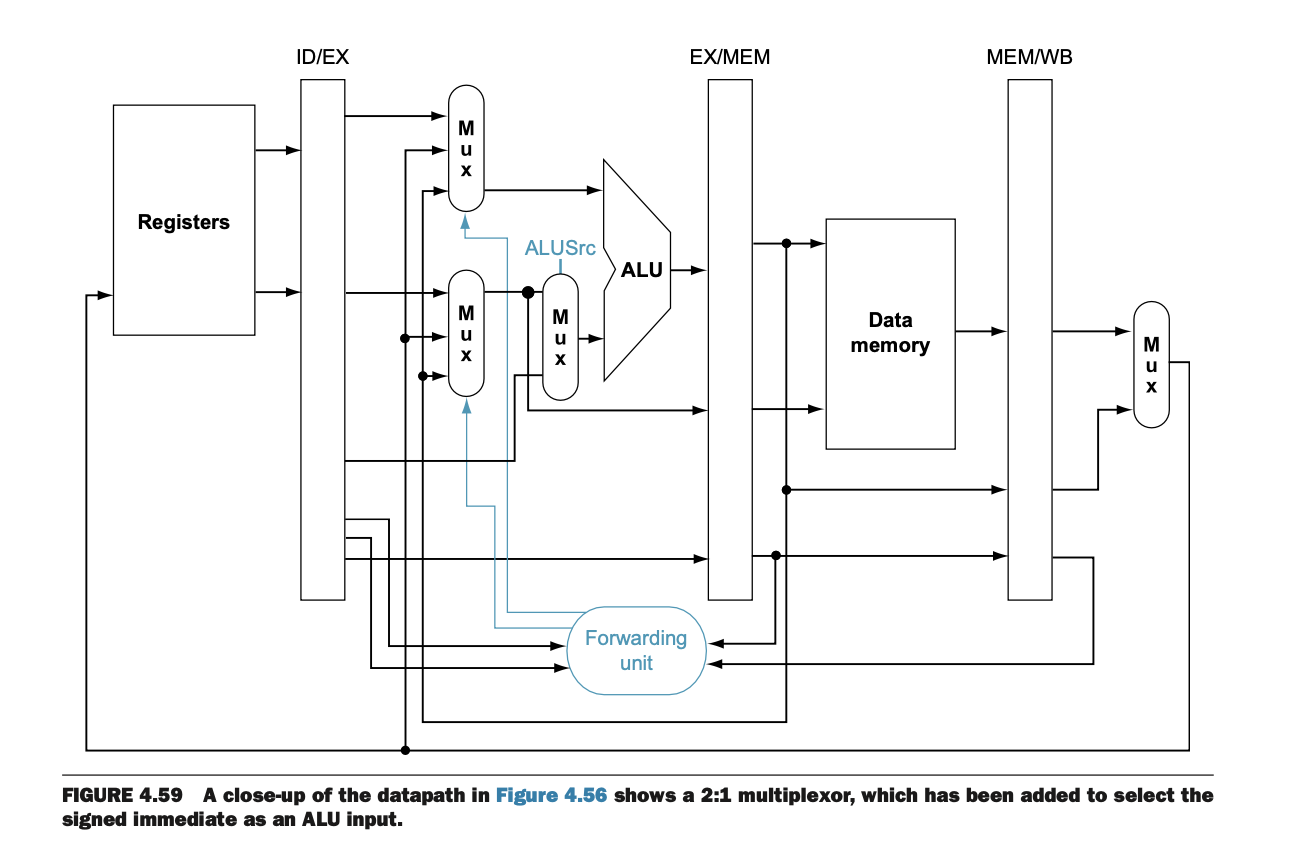
그림 4.59에서는 2:1 멀티플렉서가 어떻게 포워딩을 통해 ALU로 데이터를 전달하는지 설명한다.
ForwardA와 ForwardB는 각각 ALU의 첫 번째와 두 번째 오퍼랜드를 선택한다.
포워딩 유닛은 파이프라인 레지스터에서 나온 데이터를 ALU로 전달하여 ALU 연산을 지연 없이 진행할 수 있게 한다.
5. 결론
• 포워딩과 스톨링은 데이터 해저드를 해결하기 위해 파이프라인에서 중요한 역할을 한다.
• 포워딩은 ALU와 같은 연산 장치에 데이터를 직접 전달하여 빠르게 처리할 수 있도록 돕고, 스톨링은 데이터가 준비될 때까지 파이프라인을 지연시킨다.
• 해저드 검출 장치는 데이터 해저드를 감지하고, 필요한 시점에 스톨을 삽입하여 데이터를 정확히 읽을 수 있도록 보장한다.
• 이러한 메커니즘을 통해 RISC-V 아키텍처는 파이프라인의 효율적인 실행을 가능하게 한다.
'Book > COMPUTER ORGANIZATION AND DESIGN RISC-V' 카테고리의 다른 글
| 4. The Processor (4.10 Exceptions) (1) | 2024.11.17 |
|---|---|
| 4. The Processor (4.9 Control Hazards) (0) | 2024.11.17 |
| 4. The Processor (4.7 Pipelined Datapath and Control) (0) | 2024.11.17 |
| 4. The Processor (4.6. Data Hazard) (1) | 2024.11.15 |
| 4. The Processor (4.6. An Overview of Pipelining) (0) | 2024.11.15 |