1. Pipelining과 Instruction-Level Parallelism (ILP)
Pipelining은 여러 명령어가 동시에 실행되는 구조로, **Instruction-Level Parallelism (ILP)**을 활용하여 성능을 향상시킨다.
ILP는 명령어들 간의 병렬성을 의미하며, 이를 극대화하기 위한 두 가지 방법이 있다.
• 파이프라인 깊이를 늘려서 병렬성 증가
예를 들어, 세탁기를 세 개의 기계로 나누어 각기 다른 세탁 단계를 동시에 수행하면 전체 세탁 시간을 단축할 수 있다.
파이프라인을 확장하여 명령어를 겹쳐서 실행할 수 있도록 한다.
• Multiple Issue 기법 사용
한 클록 사이클에서 여러 명령어를 실행할 수 있도록, 여러 명령어를 동시에 발행하는 기술이다. 세탁기를 여러 대 사용해 한 번에 더 많은 세탁을 처리하는 것과 비슷하다.
2. Static Multiple Issue
Static Multiple Issue는 컴파일러가 명령어를 어떻게 발행할지를 미리 정해주는 방식이다.
컴파일러는 각 명령어가 발행되는 타이밍을 정리하여 명령어들이 충돌하지 않게 관리한다.
예시:
두 개의 명령어를 한 번에 실행하는 구조로, ALU 연산과 Data Transfer 연산이 동시에 실행될 수 있다.
이때 명령어는 반드시 한 번의 클록 사이클 내에서 실행되어야 하며, 이를 위해 추가적인 하드웨어가 필요하다.
예를 들어, 추가적인 레지스터 파일 포트와 ALU를 사용할 수 있다.
3. Dynamic Multiple Issue
Dynamic Multiple Issue는 명령어 실행 중 동적으로 결정되는 기법이다.
실행 중에 명령어들이 충돌하지 않도록 하드웨어가 자동으로 처리한다.
컴파일러는 명령어의 실행 순서를 결정하고, 하드웨어는 실행 중에 발생할 수 있는 충돌을 해결한다.
4. Speculation과 예측
Speculation은 명령어 실행의 결과를 예측하는 기법이다.
예를 들어, **브랜치 예측(branch prediction)**을 통해 분기 명령어가 실행될 때 실제 분기 여부를 예측하고, 예측된 대로 계속 명령어를 실행하는 방식이다.
만약 예측이 잘못되면 파이프라인을 플러시하여 잘못된 명령어를 제거하고 다시 실행한다.
• Speculation은 예측이 맞으면 성능을 크게 향상시킬 수 있지만, 예측이 틀리면 파이프라인을 중단하고 다시 시작해야 하기 때문에 성능에 큰 영향을 줄 수 있다.
• 예측은 컴파일러나 하드웨어가 할 수 있으며, 잘못된 예측은 “flush” 신호를 통해 처리된다.
5. Loop Unrolling
Loop Unrolling은 루프 내부의 반복을 더 효율적으로 실행하기 위해 반복문을 펼쳐서 여러 번 실행되게 만드는 기법이다.
이를 통해 파이프라인에서 병렬 실행을 더 많이 할 수 있어 성능을 개선할 수 있다.
• 예시
만약 add와 store 명령이 반복문 안에 있다면, loop unrolling을 통해 이들을 각각 독립적으로 실행되도록 만들어 성능을 향상시킨다.
예를 들어, 한 번에 두 번의 명령어를 동시에 실행시켜 더 빠르게 루프를 처리한다.
6. 다양한 병렬성 기법들
Multiple-Issue Pipeline에서 병렬 처리 성능을 높이기 위한 추가적인 기법들이 존재한다.
예를 들어, **Very Long Instruction Word (VLIW)**는 하나의 명령어에 여러 개의 연산을 포함시키는 방식이다.
이 방식은 컴파일러가 명령어를 준비하고 하드웨어는 그 명령어들을 동시에 실행한다.


• Figure 4.69는 Static Two-Issue Pipeline을 보여준다.
ALU와 Data Transfer 명령어가 동시에 발행되어 파이프라인을 효율적으로 사용하는 구조이다.
이는 load와 store 연산을 동시에 처리할 수 있다.
• Figure 4.70은 Static Two-Issue Datapath로, 명령어 두 개를 동시에 처리하기 위한 추가적인 하드웨어 자원을 포함한다.
예를 들어, register 파일에서 두 개의 레지스터를 읽고 쓸 수 있는 포트와 두 개의 ALU가 동시에 작동할 수 있다.
동적 다중 명령 처리 (Dynamic Multiple-Issue Processors)
동적 다중 명령 처리기, 또는 슈퍼스칼라 프로세서라고도 하는 이 기술은 여러 명령어를 동시에 처리할 수 있도록 설계된 프로세서이다.
가장 기본적인 형태에서는 한 클럭 주기 내에 두 개 이상의 명령어를 실행하는 방식이다.
동적 파이프라인 스케줄링(Dynamic Pipeline Scheduling) 기법을 활용하여, 명령어들이 실행될 순서를 동적으로 결정할 수 있다.
이 방식은 **데이터 해저드(Data Hazard)**를 피하고 명령어들을 최적으로 실행되도록 한다.
예시 코드:
lw x31, 0(x20)
add x31, x31, x2
여기서 lw 명령이 먼저 실행되는데, add 명령은 lw 명령의 결과를 기다려야 한다.
이 경우, 동적 파이프라인 스케줄링은 add 명령을 다른 자원을 사용해 병렬로 처리하면서 데이터 의존성을 해결한다.
동적 파이프라인 스케줄링 (Dynamic Pipeline Scheduling)
동적 파이프라인 스케줄링은 각 명령어를 실행하기 위해 어떤 명령어가 먼저 실행되어야 하는지, 어느 명령어가 데이터 의존성 문제로 대기해야 하는지 동적으로 선택하는 방식이다.
이를 위해 프로세서는 명령어를 예약 스테이션(Reservation Stations) 에 저장하고, 해당 명령어가 실행 가능한 시점이 오면 실행을 시작한다.
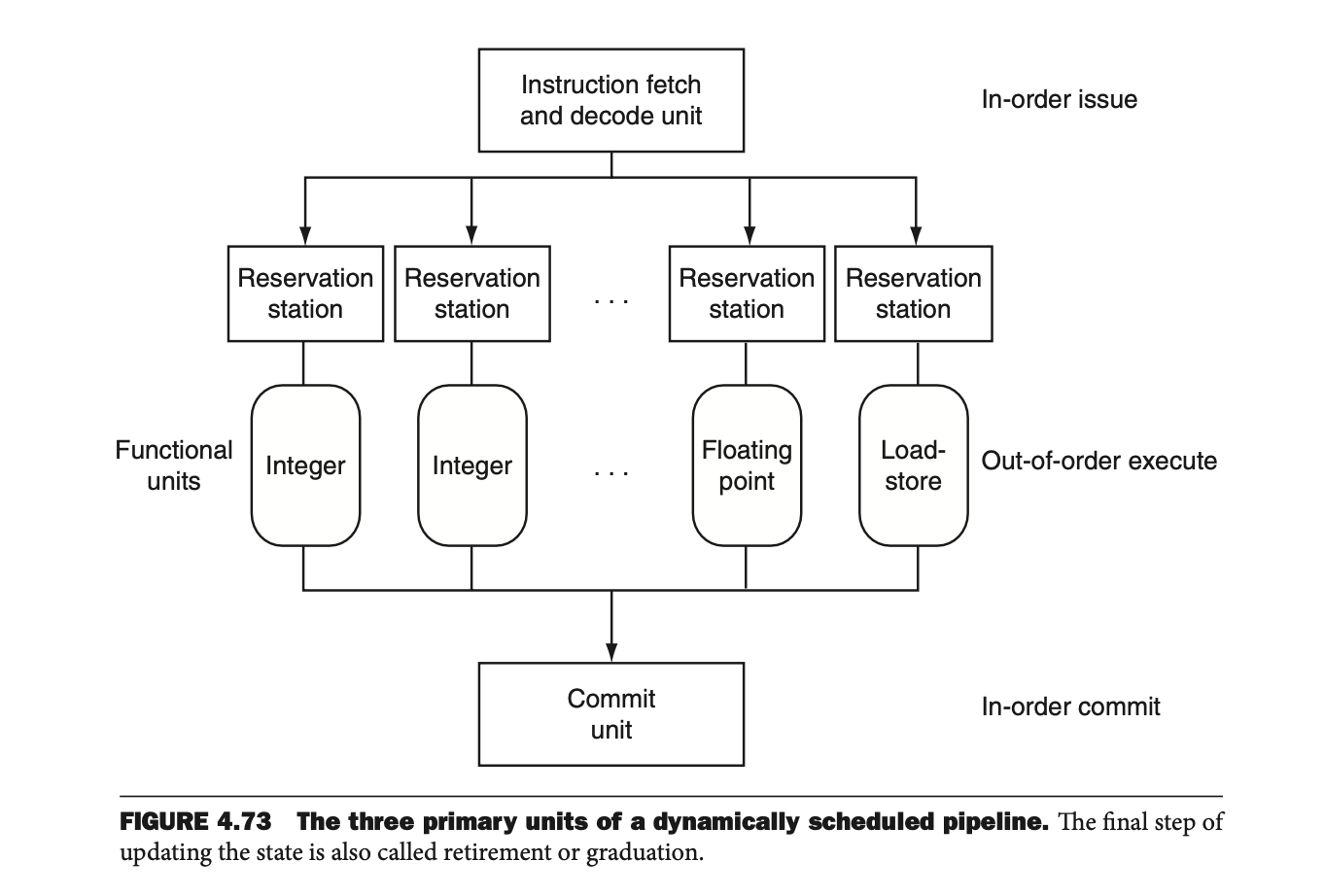
• Figure 4.73
동적 파이프라인에서 명령어를 예약 스테이션에 저장하고, 그 명령어가 실행될 때까지 기다리는 구조를 보여준다. 이 구조에서 명령어가 완료될 때까지 기다리는 방법을 레지스터 리네이밍(Register Renaming) 이라고 한다. 이는 레지스터 충돌을 방지하기 위한 방법이다.
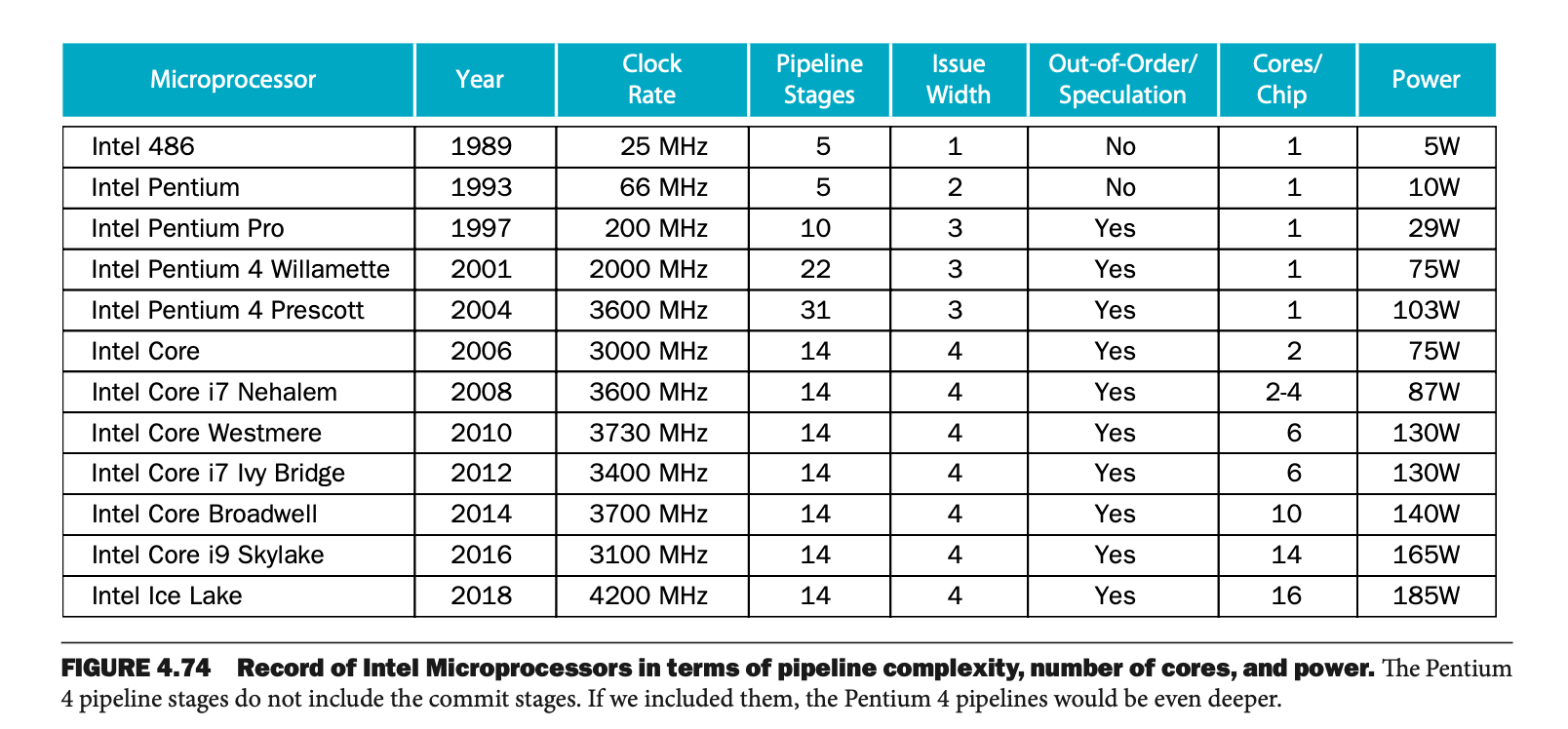
• Figure 4.74
명령어들이 여러 가지 파이프라인에서 동시에 처리되는 과정에서 발생할 수 있는 데이터 의존성 문제를 해결하는 방법을 설명한다. 데이터 의존성 해소는 동적 파이프라인의 핵심적인 문제다.
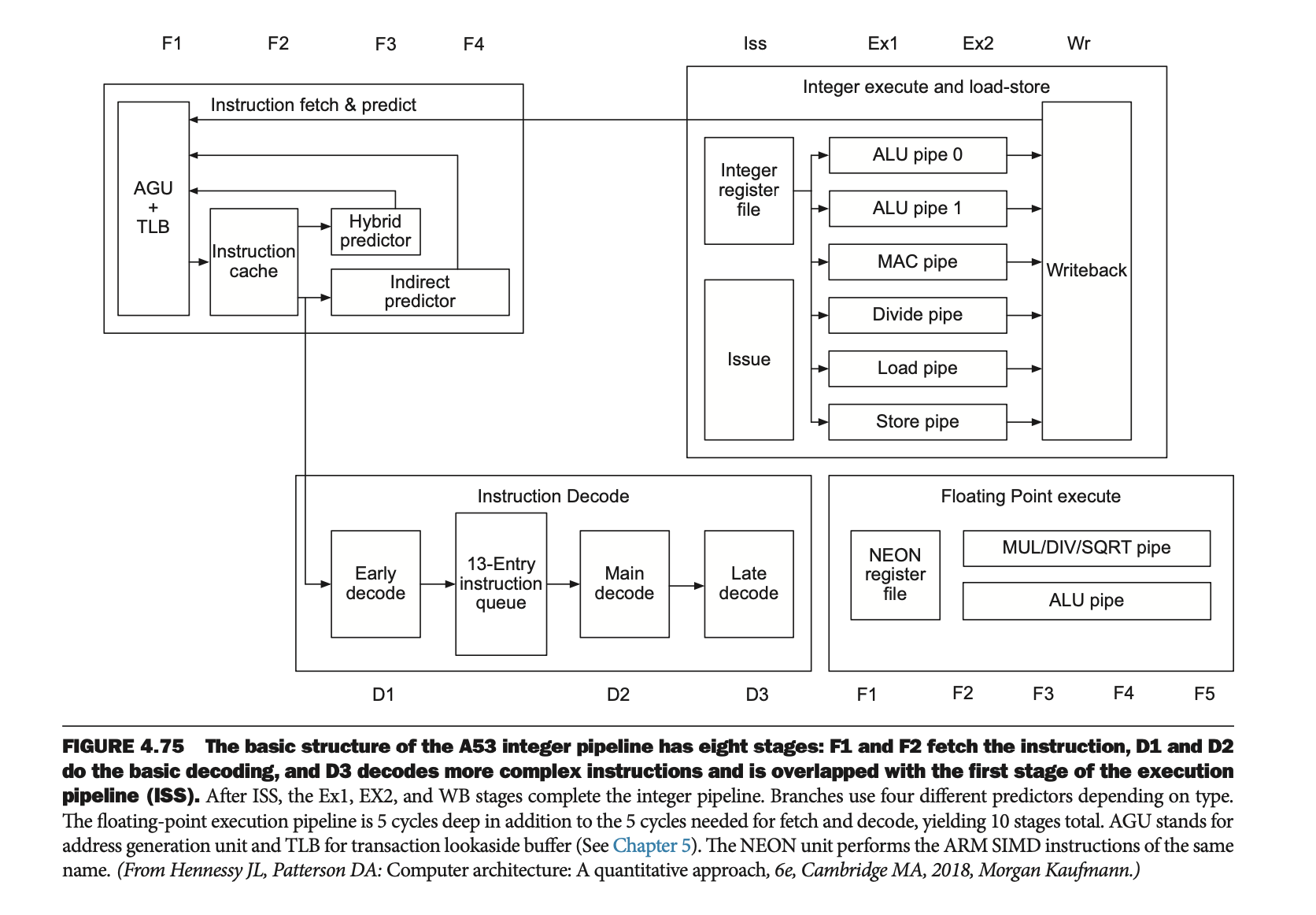
• Figure 4.75
실제 ARM A53 프로세서의 구조를 예시로 보여주며, 복잡한 동적 파이프라인에서 어떻게 여러 명령어를 동시에 처리할 수 있는지 설명한다.

• Figure 4.71
정적 다중 명령어 처리 (Static Multiple Issue)의 예시 코드 스케줄링을 보여준다. 이 예시는 정적 방식으로 명령어들을 처리하는 방식이다.
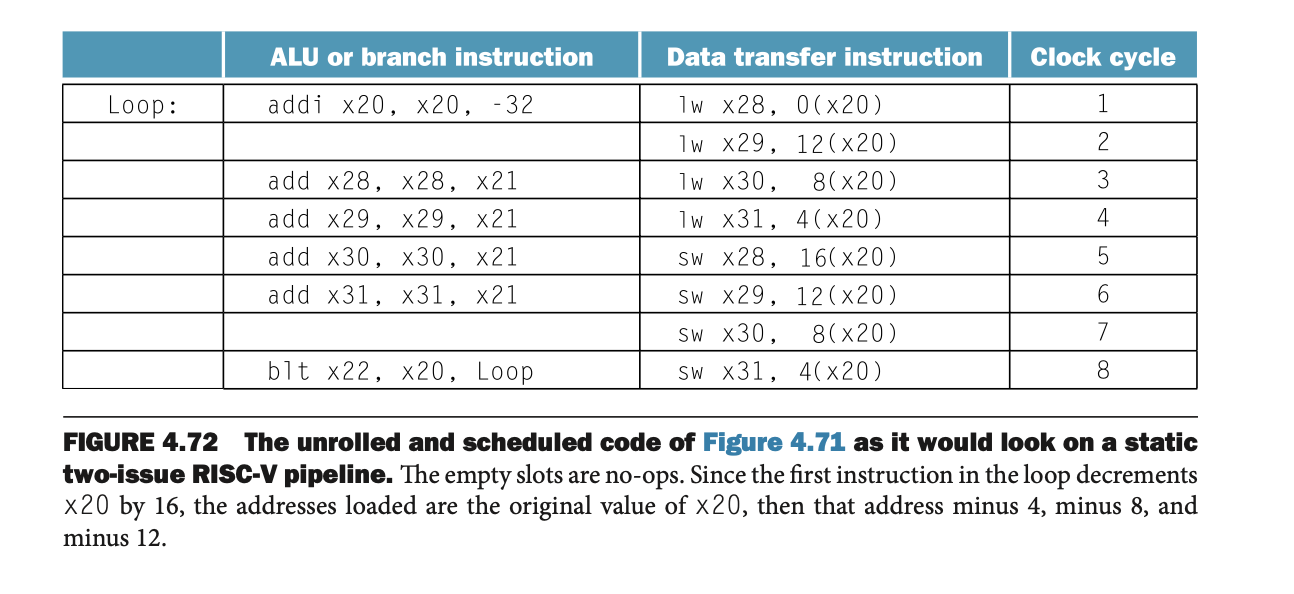
• Figure 4.72
루프 언롤링(Loop Unrolling) 기법을 사용하여 코드의 성능을 향상시키는 방식이다. 이 방식은 반복되는 코드를 분해하여 병렬 처리가 가능하도록 한다.
4.10 예외 처리 (Exceptions Handling)
예외 처리는 예기치 않은 상황이 발생했을 때 프로그램이 정상적으로 실행되지 않도록 하는 메커니즘이다.
예를 들어, 정의되지 않은 명령어나 하드웨어 고장이 발생했을 때 이를 처리하는 방식이다.
예외가 발생하면, SEPC (Supervisor Exception Program Counter) 레지스터에 문제가 발생한 명령어의 주소를 저장하고,
이 예외 처리 루틴으로 분기한다.
예시:
add x11, x12, x13 // 오류가 발생한 명령어
이 예시에서 오류가 발생하면, 해당 명령어의 주소가 SEPC 레지스터에 저장되고, 예외 처리 루틴으로 분기한다.
Check Yourself 문제와 해설
• 문제: 주어진 기술들이 주로 소프트웨어 중심의 접근법과 하드웨어 중심의 접근법 중 어떤 것에 속하는지 구별하기.
• 답안:
• Branch prediction → 하드웨어 중심
• Multiple issue → 하드웨어 중심
• VLIW (Very Long Instruction Word) → 하드웨어 중심
• Superscalar → 하드웨어 중심
• Dynamic scheduling → 하드웨어 중심
• Speculation → 하드웨어 중심
• Reorder buffer → 하드웨어 중심
• Register renaming → 하드웨어 중심
이 문제는 하드웨어 중심의 ILP(Instruction Level Parallelism)를 증가시키기 위해 사용되는 다양한 기술들을 구별하는 문제다. 대부분의 기술들은 하드웨어에서 자동으로 처리되며, 소프트웨어는 이를 최적화하는 역할을 한다.
위 설명은 컴퓨터 구조에서 다루는 다양한 파이프라인 기법과 예외 처리, 동적 명령어 스케줄링을 이해하는 데 중요한 개념들을 다루고 있다.
1. 클럭 속도 (Clock Rate):
• 5단계 파이프라인: 5단계 파이프라인(명령어 가져오기, 디코드, 실행, 메모리 액세스, 결과 쓰기)은 각 명령이 지나가는 단계가 많아지지만, 각 단계는 상대적으로 짧습니다. 각 단계에서 처리되는 작업이 짧기 때문에 클럭 주파수(클럭 속도)가 높아지며, 전체 파이프라인을 더 빠르게 동작시킬 수 있습니다.
• 3단계 파이프라인: 3단계 파이프라인은 단계 수가 적어 각 단계가 상대적으로 길어지게 되며, 따라서 클럭 속도는 낮아지게 됩니다. 하지만, 각 단계에서 처리하는 시간이 길어지므로 각각의 명령이 지나갈 수 있는 시간은 더 길어지므로, 의존성 처리나 병목 현상은 줄어들 수 있습니다.
2. 레지스터 읽기/쓰기 데이터 위험 (Register Write/Read Data Hazards):
• 5단계 파이프라인에서는 주로 포워딩(forwarding) 방식을 사용해 이러한 위험을 처리합니다. 포워딩은 결과가 나오는 즉시, 그 결과를 다음 명령어에서 사용할 수 있도록 직접 전달해 주는 방식입니다. 예를 들어, 실행 단계(EX)에서 나오는 결과를 메모리 액세스(MEM) 단계로 넘기는 것이 아니라, 바로 그 다음 명령어가 사용할 수 있게 합니다.
• 3단계 파이프라인에서도 이와 같은 데이터 위험은 여전히 발생할 수 있으며, 포워딩 방식은 여전히 유효합니다. 포워딩을 사용하지 않으면 파이프라인을 멈추는(스톨) 방식으로 처리해야 하며, 이는 두 파이프라인 모두에서 발생할 수 있습니다. 하지만 3단계 파이프라인은 구조가 간단하므로 상대적으로 적은 스톨을 발생시킬 수 있습니다.
3. 로드-사용 데이터 위험 (Load-Use Data Hazards):
• 5단계 파이프라인에서 로드-사용 데이터 위험은 로드 명령에서 데이터를 읽은 후, 그 데이터를 바로 다음 명령어에서 사용하려고 할 때 발생합니다. 이 문제는 파이프라인 내에서 포워딩으로 처리할 수 있습니다. 즉, 로드 명령이 완료되기 전에 그 값을 바로 다음 명령어로 전달해주는 방식입니다.
• 3단계 파이프라인에서도 로드-사용 데이터 위험은 여전히 발생하며, 이 경우에도 포워딩을 사용해 처리할 수 있습니다. 다만, 3단계 파이프라인에서는 각 단계가 길기 때문에 포워딩의 구현은 조금 더 복잡할 수 있습니다. 만약 포워딩을 사용하지 않는다면, 파이프라인을 멈추고(스톨) 기다리는 방식으로 해결해야 할 수 있습니다.
4. 제어 위험 (Control Hazards):
• 5단계 파이프라인에서는 **분기 명령어(branch instruction)**가 있을 경우, 분기 명령어가 실행되는 단계(일반적으로 메모리 액세스(MEM) 단계)에서 실행이 완료된 후에야 분기의 결과를 알 수 있습니다. 따라서, 그 전까지는 다른 명령어를 실행할 수 없습니다. 이 문제는 포워딩이나 스톨 방법을 통해 해결할 수 있습니다.
• 3단계 파이프라인에서도 제어 위험은 여전히 존재하며, 이 문제를 해결하기 위해서는 분기 예측(branch prediction)을 활용하거나, 분기 후 명령어를 실행하지 않고 기다리는 방법을 사용할 수 있습니다. 이 때, 제어 위험을 줄이기 위해서는 분기 예측 방식이 중요합니다.
5. CPI (클럭 주기당 명령어 수):
• 5단계 파이프라인은 각 명령어가 더 많은 단계를 거쳐 실행되므로 CPI가 높을 수 있습니다. 그러나 각 단계가 짧아서 더 많은 명령어를 동시에 실행할 수 있기 때문에 전반적으로 더 많은 명령어를 처리할 수 있습니다.
• 3단계 파이프라인은 각 단계가 길어지지만 단계 수가 적기 때문에, 한 번에 처리할 수 있는 명령어 수가 적어져서 CPI가 더 낮을 수 있습니다. 즉, 성능은 약간 떨어질 수 있습니다.
정리:
3단계 파이프라인은 구조가 간단하고 클럭 속도가 낮지만, 명령어 처리 순서가 상대적으로 간단하므로, 스톨이나 포워딩을 적게 사용해야 할 수 있습니다. 반면, 5단계 파이프라인은 각 단계를 더 세분화하여 클럭 속도를 빠르게 할 수 있지만, 명령어 처리에 더 많은 스톨과 포워딩을 사용해야 할 수 있습니다.
'Book > COMPUTER ORGANIZATION AND DESIGN RISC-V' 카테고리의 다른 글
| 5.2 Memory Technologies (0) | 2024.11.20 |
|---|---|
| 5. Large and Fast: Exploiting Memory Hierarchy(5.1 Introduction) (0) | 2024.11.20 |
| 4. The Processor (4.10 Exceptions) (1) | 2024.11.17 |
| 4. The Processor (4.9 Control Hazards) (0) | 2024.11.17 |
| 4. The Processor (4.8 Data Hazards:Forwarding versus Stalling) (1) | 2024.11.17 |