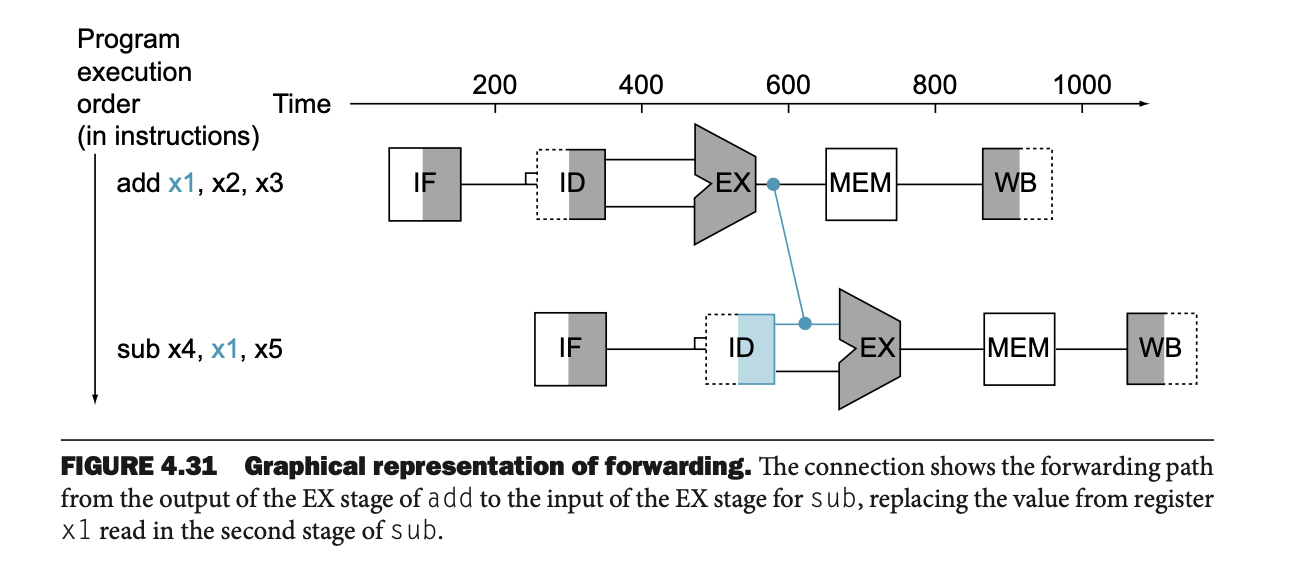
Data Hazard Data Hazard는 이전 명령어의 실행 결과가 다음 명령어에서 필요한 경우 발생한다.예를 들어, 덧셈 명령어의 결과를 뺄셈 명령어에서 사용하는 경우, 덧셈 명령어가 끝나지 않으면 뺄셈 명령어가 실행되지 못한다. 구조적 위험(Structural Hazard) • 구조적 위험은 하드웨어 리소스가 부족할 때 발생한다.예를 들어, 파이프라인에 메모리가 하나밖에 없을 때 두 명령어가 동시에 메모리를 참조하려고 하면 구조적 위험이 발생한다.이 위험을 피하려면 메모리 리소스를 추가하거나, 각 명령어가 사용하는 리소스를 효율적으로 분배해야 한다. • 예시: 세탁기와 건조기를 하나의 장비로 사용할 경우 세탁과 건조를 동시에 처리할 수 없게 되어 구조적 위험이 발생한다. 데이터 위험(Dat..