1. Cache (캐시):
컴퓨터에서 프로세서와 메인 메모리 사이에 위치하여 데이터 접근 속도를 향상시키는 작고 빠른 임시 저장소이다.
캐시는 데이터를 저장하고, 필요한 데이터를 메모리에서 가져오지 않고 빠르게 읽을 수 있도록 한다.
캐시는 지역성(Locality) 원리를 기반으로 작동한다.
2. Direct-Mapped Cache (직접 매핑 캐시):
캐시 구조 중 하나로, 각 메모리 주소가 캐시의 특정 위치에 고정적으로 매핑되는 방식이다.
한 번에 특정 메모리 블록만 특정 캐시 슬롯에 저장될 수 있다.
3. Tag (태그):
캐시에 저장된 데이터가 메모리의 어떤 블록에서 왔는지 식별하기 위한 추가 정보이다.
메모리 주소의 일부가 태그로 사용된다.
4. Valid Bit (유효 비트):
캐시 블록이 유효한 데이터를 포함하는지 여부를 나타낸다.
유효 비트가 0이면, 해당 캐시 엔트리는 무효로 간주된다.
5. Cache Miss:
프로세서가 캐시에 원하는 데이터를 찾지 못했을 때 발생하는 상황이다.
이 경우, 데이터는 메인 메모리에서 가져와 캐시에 저장된다.
캐시의 기본 개념
캐시는 1960년대에 등장했으며, 프로세서가 데이터를 더 빠르게 접근할 수 있도록 설계된 메모리 계층 구조의 일부이다.
캐시의 주요 목표는 지역성의 원리(Locality Principle)를 활용하여 자주 접근하는 데이터를 가까운 곳에 저장해 처리 속도를 높이는 것이다.
• 지역성의 원리:
1. 시간적 지역성(Temporal Locality): 최근 사용된 데이터는 곧 다시 사용될 가능성이 높다.
2. 공간적 지역성(Spatial Locality): 특정 데이터가 사용되면, 근처의 데이터도 곧 사용될 가능성이 높다.
본문에서는 매우 간단한 직접 매핑 캐시를 예로 들어 설명하고 있다. 여기서 각 메모리 요청은 1단어(word)이며, 캐시 블록도 1단어로 구성된다.
캐시 동작의 기본 이해
1. 데이터 요청 전 (Before Reference to ):
캐시는 이전에 사용된 데이터 (x1, x2, x3, . . ., x(n-1))를 저장하고 있습니다. 프로세서가 새로운 데이터 을 요청하면, 캐시는 해당 데이터가 캐시에 있는지 확인합니다.
2. 캐시 미스 (Cache Miss):
이 캐시에 없다면, 데이터를 메인 메모리에서 가져와 캐시에 저장하고, 프로세서에 전달합니다.
직접 매핑 캐시의 기본 구조
• 매핑 방식:
직접 매핑 캐시는 메모리 주소를 기반으로 캐시 위치를 결정한다. 매핑은 다음 수식을 사용한다.
(Block Address) mod (Number of Blocks in Cache)
이 수식은 메모리의 특정 주소가 캐시의 어떤 위치에 저장될지 결정한다.
예를 들어, 8개의 캐시 블록이 있을 때, 메모리 주소의 하위 3비트가 캐시의 블록 위치를 결정한다.

Figure 5.7: 캐시 동작의 예시
a. 데이터 요청 전 (Before Reference to ):
• 캐시는 이전 데이터 (x1, x2, x3, . . ., x(n-1))를 저장하고 있다.
• 프로세서는 새로운 데이터 xn을 요청한다.
b. 데이터 요청 후 (After Reference to ):
• xn은 캐시에 없었기 때문에, 캐시는 캐시 미스를 경험한다.
• xn은 메모리에서 가져와 캐시에 저장되고, 가장 오래된 데이터가 퇴출된다.

Figure 5.8: 직접 매핑 캐시의 주소 매핑
이 그림은 8개의 캐시 블록을 가진 직접 매핑 캐시를 예로 들어 설명한다.
1. 메모리 주소의 하위 3비트가 캐시 위치를 결정한다. 예를 들어
• 메모리 주소 00001(2진수)는 캐시 블록 1에 매핑된다.
• 주소 10101(2진수) 또한 같은 캐시 블록 1에 매핑된다. (충돌 발생 가능)
2. 동일한 캐시 블록에 여러 메모리 주소가 매핑될 경우, 가장 최근 데이터를 덮어쓴다.
3. 문제 풀이 및 해설
1. 문제: Xn 요청 시 캐시 미스가 발생하는 이유는?
• 캐시에 이 없기 때문
• 데이터는 메모리에서 가져와 캐시에 저장되어야 함
2. 문제: 이 캐시의 어느 위치에 저장될지 결정하는 방식은?
• 수식: (Block Address) mod (Number of Blocks in Cache)
• 예: 의 주소가 29이고, 캐시 블록이 8개라면, 29mod8 = 5
, 따라서 캐시 블록 5에 저장된다.
4. 추가 설명
캐시 성능의 핵심
1. Cache Hit vs Cache Miss:
• Hit: 캐시에 요청한 데이터가 있는 경우 → 빠르게 응답.
• Miss: 데이터가 없는 경우 → 메인 메모리 접근으로 느려짐.
2. 태그(Tag)와 유효 비트(Valid Bit):
• 태그는 데이터가 메모리의 어느 블록에서 왔는지 확인하는 데 사용됨
• 유효 비트는 캐시 블록이 유효한 데이터를 포함하는지 여부를 나타냄

“The Big Picture” 요약
캐시는 **예측(Prediction)**과 밀접한 관련이 있다.
• 지역성 원리를 기반으로 미래에 필요한 데이터를 미리 캐시에 저장하여 성능을 높인다.
• 현대 컴퓨터에서는 캐시의 예측 성공률(Cache Hit Rate)이 95% 이상으로 매우 높다.
캐시 접근 과정
캐시가 비어 있는 상태에서 시작하여, 8블록 직접 매핑 캐시의 동작을 설명한다.
1. 참조 주소의 하위 3비트를 사용해 캐시 블록을 결정한다. (Block Address mod Number of Cache Blocks)
2. 첫 몇 번의 요청은 캐시 미스를 발생시킨다. 요청된 데이터는 메인 메모리에서 가져와 캐시에 저장된다.
3. 데이터가 이미 캐시에 존재하면 캐시 히트가 발생한다.

예를 들어 주소 22(10110)를 참조하며나,
10110 mod 8 = 6
처음 요청이므로 캐시 미스를 발생시키고 -> 데이터를 메모리에서 가져와 캐시 플록 6에 저장.

위 그림은 캐시의 동작 과정을 보여준다.
1. (a) 초기 상태 :
모든 valid bit가 0으로 설정되어 있어 캐시는 비어있는 상태이다.
2. (b) 10110 요청:
뒤 3비트(110)->블록 6에 데이터 저장.
태그는 10, 데이터는 memory(110110)
위와 같은 과정이 반복되고, 충돌 발생 시 기존의 것이 없어진다.

메모리의 주소는 다음과 같이 나뉜다:
1. Tag 필드 : 데이터가 메모리의 어느 부분에서 왔는지 확인한다.
2. Index 필드 : 캐시 블록을 선택하는데 사용된다.
3. Baye Offset : 캐시 블록 내에서의 데이터 위치를 결정한다.
캐시 크기 계산
블록 크기 : 1word -> 4byte
캐시 블록 수 : 4KB 캐시의 경우 -> 1024블록 = 2^10
태그 크기 : 32 - 캐시 블록 수 의 비트 - 블록 크기의 비트
캐시 블록 수의 비트 = log2(1024) = 10
블록 크기의 비트 = log2(4) = 2
총 비트 = 1024 * (32 + 1 - 10 - 2) = 21504(21KB)

문제:
• 16 KiB 크기의 직접 매핑 캐시에서, 데이터와 블록 크기(block size)가 각각 4단어인 경우, 총 필요한 비트 수를 계산하시오.
• 각 메모리 주소는 64비트 주소를 사용한다.
1. 주어진 조건 정리
• 캐시 크기: 16Kib = 2^14 bytes
• 블록 크기: 4word = 4*4 = 16bytes = 2^4 bytes
• 캐시 블록 수: 2^10 blocks
• 메모리 주소 크기: 64bits
2. 계산할 비트 구성 요소 정의
-데이터 비트 : 128bits
-Tag 비트 : 64 - 10 - 4 - 2 = 48bits
- valid 비트 : 1bit
3. total 비트 계산
-블록 하나당 필요한 비트
block = data + tag + valid = 128 + 48 + 1 = 177bits
Total = 177 * 2^10 = 181,248 (약 22.4KiB)
순수한 데이터 저장 비트보다 약 1.4 더 필요하다.

example 문제 : 블록 크기가 16바이트이고, 64개의 블록이 있는 캐시에서 주소 1200은 어느 캐시 블록에 매핑되는가?
1. 블록 주소 계산
블록 크기가 16bytes 이므로, 각 블록은 16개의 연속 주소를 포함한다.
Block Address = Byte Address/ Bytes per Block = 1200/16 = 75
2. 캐시 블록 매핑
Cache Block Number = Block Address mod Number of Cache Blocks
Cache Block Number = 75 mod 64 = 11
-> 블록번호 11에 매핑된다.
3. 블록의 주소 범위 계산
블록의 시작주소 = Block Address * Byter per Block = 75*16 = 1200
블록의 종료주소 = Start Address + Bytes per Block -1 = 1215
따라서 블록 75는 주소 범위 1200~1215를 포함한다.

위 그림은 블록의 크기에 따른 missrate를 보여준다.
일정 사이즈까지는 블록의 크기를 증가시키면 공간적 지역성을 더 잘 활용하므로 missrate가 감소하는 것을 볼 수 있다.
하지만, 블록 크기를 과하게 증가시킬 경우 캐시의 유효 블록 수가 감소하여 충돌이 발생하고,
결과적으로 missrate가 다시 증가하게 된다.
추가 최적화
Early Restart : 요청된 데이터를 먼저 반환하여 성능을 향상시킨다.
Critical Word First : 요청된 데이터를 먼저 전송하고, 나머지 블록 데이터를 순서대로 가져온다.
Handling Cache Misses
캐시 미스란?
캐시에 요청한 데이터가 없을 때 발생하는 상황.
이때 데이터는 메인 메모리(혹은 하위 캐시) 에서 가져와야 하며, 이는 메모리 접근 시간을 증가시킨다.
캐시 미스의 기본 처리 과정
1. 명령어 캐시 미스의 처리:
프로세서가 실행해야 할 명령어가 캐시에 없을 때 발생한다.
• 명령어가 캐시에 없다면, 프로세서를 정지(stall)시키고, 데이터를 메인 메모리에서 가져온다.
• 명령어의 주소는 **프로그램 카운터(Program Counter, PC)**에 의해 결정된다
예: 실행 중인 명령어의 주소가 PC - 4 로 계산된다.
2. 구체적인 단계:
캐시 미스 시 명령어를 처리하는 4단계:
• Step 1: PC의 주소를 메인 메모리에 보낸다.
• Step 2: 메인 메모리가 요청된 명령어를 읽고, 데이터를 반환한다.
• Step 3: 반환된 데이터를 캐시에 저장하며, 주소의 상위 비트를 **태그(Tag)**로 추가하고 **유효 비트(Valid Bit)**를 1로 설정한다.
• Step 4: 명령어 실행을 재개하여 정상적으로 동작한다.

순차 처리(In-order Execution) vs. 비순차 처리(Out-of-Order Execution)
• 순차 처리(In-order):
• 단순한 설계로, 캐시 미스가 발생하면 프로세서 전체를 멈춘다.
• 비순차 처리(Out-of-Order):
• 고급 프로세서는 캐시 미스 동안 독립적인 명령어를 계속 실행하여 효율성을 높인다.
Handling Writes
읽기와 달리 쓰기는 캐시에 데이터를 저장한 후 메인 메모리 동기화가 필요하다.
캐시에 메모리 간 데이터 일관성을 유지하려면 특정 정책이 필요하다.
쓰기 동작의 주요 정책
1. Write-Through (직접 쓰기):
• 캐시와 메모리 동시에 쓰기를 수행한다.
• 데이터 일관성(consistency)을 보장한다.
• 단점: 메인 메모리 접근이 빈번하므로 성능 저하가 발생할 수 있다.
2. Write-Back (지연 쓰기):
• 데이터를 캐시에만 쓰고, 수정된 블록이 캐시에서 퇴출될 때 메모리에 쓴다.
• 성능이 향상되지만, 복잡한 설계가 필요하다.
3. Write Buffer (쓰기 버퍼):
• 캐시와 메모리 쓰기 사이의 중간 버퍼를 사용하여 성능을 개선한다.
• 데이터를 버퍼에 저장해두고, 메모리가 여유로워질 때 천천히 메모리에 쓴다.
• 장점: 쓰기 병목 현상을 줄이고, 프로세서가 쓰기 작업 동안 계속 실행할 수 있다.
• 단점: 버퍼가 가득 차면 프로세서가 멈추는 문제가 발생할 수 있다.
캐시 미스와 쓰기 정책의 상호작용
1. Write Allocate (쓰기 할당):
• 쓰기 미스가 발생하면, 해당 데이터 블록을 메모리에서 읽어 캐시에 저장한다.
• **공간적 지역성(Spatial Locality)**을 활용한다.
2. No Write Allocate (비쓰기 할당):
• 쓰기 미스가 발생해도 데이터를 캐시에 저장하지 않고, 메모리에 직접 쓴다.
• 쓰기 버퍼와 함께 사용되는 경우가 많다.
An Example Cache: The Intrinsity FastMATH Processor
Intrinsity FastMATH의 특징
• 16 KiB 데이터 캐시와 명령어 캐시를 사용하여 명령어와 데이터를 독립적으로 관리한다.
• 캐시는 각각 256개의 블록을 포함하며, 각 블록은 **16단어(512비트)**로 구성된다.
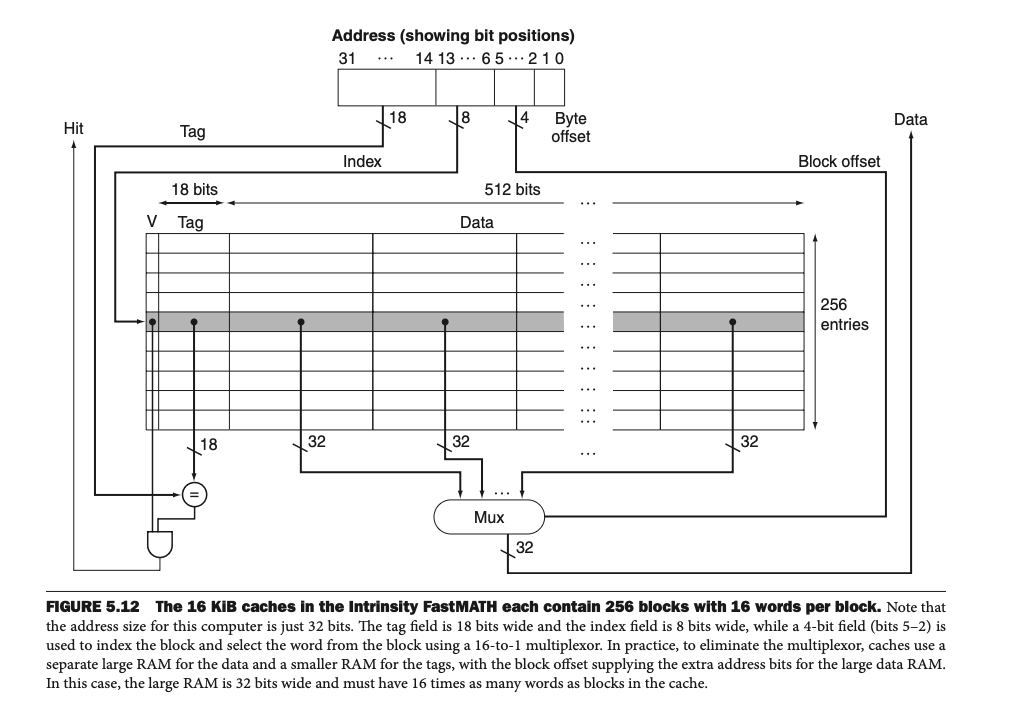
Figure 5.12: Intrinsity FastMATH 캐시 설계
이 그림은 Intrinsity FastMATH 프로세서의 데이터 캐시 설계를 보여준다.
이 프로세서는 16 KiB 데이터 캐시와 256개의 블록, **블록당 16단어(512비트)**로 구성되어 있다.
각 캐시가 데이터와 명령어를 따로 관리하는 분리 캐시(split cache) 구조를 채택하여 병렬 처리가 가능하다.
1. 메모리 주소의 분해 (Address Breakdown)
캐시는 데이터를 저장하고 관리하기 위해 32비트 메모리 주소를 세 가지 부분으로 나눈다:
1. 태그(Tag):
• 상위 18비트를 사용한다.
• 메모리 주소에서 특정 블록을 구별하는 데 사용된다.
• 예:
만약 두 메모리 주소가 같은 캐시 블록 인덱스(Index)로 매핑되었을 경우, 태그를 비교해 요청한 데이터가 현재 캐시에 있는지 확인한다.
2. 인덱스(Index):
• 중간 8비트를 사용한다.
• 캐시 블록을 선택한다.
• 256개의 캐시 블록이 있으므로, log_2(256) = 8 비트가 필요하다
3. 블록 오프셋(Block Offset):
• 하위 4비트를 사용한다.
• 선택한 블록 내의 특정 단어(32비트 데이터)의 위치를 나타낸다.
• 예: 블록당 16단어가 있으므로, log_2(16) = 4 비트가 필요하다.
2. 캐시 구성 요소
1. Valid Bit (유효 비트):
• 캐시 블록이 유효한 데이터를 포함하는지 여부를 나타낸다.
• 유효 비트가 0이면, 해당 캐시 엔트리는 비어 있거나 오래된 데이터로 간주된다.
2. Tag Field (태그 필드):
• 메모리 주소의 상위 18비트를 저장하여, 해당 블록이 메모리의 어느 주소에서 왔는지 확인한다.
3. Data Field (데이터 필드):
• 블록 내 저장된 데이터(16단어, 총 512비트)를 저장한다.
• 데이터를 캐시에 읽거나 쓸 때 이 필드가 사용된다.
4. Multiplexer (멀티플렉서):
• 선택된 캐시 블록에서 원하는 단어(블록 오프셋으로 지정된)를 선택한다.
3. 캐시 히트와 미스 처리
캐시 히트 처리
• 캐시가 요청된 주소를 받으면, 해당 주소를 아래와 같은 순서로 처리한다.
1. 인덱스(Index)를 사용해 블록 선택:
8비트 인덱스를 사용하여 256개의 블록 중 하나를 선택한다.
2. 태그(Tag)를 비교:
선택된 블록의 태그 필드와 요청된 주소의 태그를 비교한다.
• 같으면 캐시 히트(Cache Hit): 요청된 데이터는 캐시에 있음.
• 다르면 캐시 미스(Cache Miss): 요청된 데이터는 캐시에 없음.
3. 블록 오프셋(Block Offset)으로 단어 선택:
멀티플렉서를 통해 블록 내의 특정 단어를 선택한다.
캐시 미스 처리
• 요청된 데이터가 캐시에 없는 경우:
1. 메모리 주소를 메인 메모리로 보낸다.
2. 메인 메모리에서 데이터를 가져온다.
3. 데이터를 캐시에 저장하면서 태그 필드와 유효 비트를 갱신한다.
4. 요청된 데이터를 프로세서에 전달한다.
4. 데이터 읽기(Read)
데이터를 읽을 때의 동작:
1. 프로세서에서 요청된 주소를 캐시에 전송한다.
• 명령어 캐시는 PC(Program Counter)에서 주소를 가져온다.
• 데이터 캐시는 ALU(Arithmetic Logic Unit)에서 주소를 가져온다.
2. 인덱스를 기반으로 캐시 블록을 선택한다.
3. 태그 비교를 통해 캐시 히트 여부 결정:
• 태그가 일치하고 유효 비트가 1이면 요청된 데이터가 캐시에 존재한다.
4. 블록 오프셋을 사용해 블록 내 데이터 반환:
• 멀티플렉서를 통해 선택된 단어를 프로세서로 반환한다.
5. 데이터 쓰기(Write)
쓰기 정책: Write-Through와 Write-Back
• Write-Through:
데이터를 캐시에 쓰는 동시에 메모리에도 동일한 데이터를 쓴다.
• 장점: 캐시와 메모리의 데이터 일관성을 유지한다.
• 단점: 메모리 접근 횟수가 많아 성능 저하가 발생할 수 있다.
• Write-Back:
데이터를 캐시에만 저장하고, 해당 캐시 블록이 교체될 때 메모리에 쓴다.
• 장점: 성능이 향상된다.
• 단점: 데이터 일관성을 즉시 보장하지 않으므로, 추가 관리가 필요하다.

6. 캐시 미스율 분석 (Figure 5.13)
미스율 통계
Intrinsity FastMATH 프로세서에서 측정된 캐시 미스율:
• 명령어 캐시 미스율: 0.4%
• 데이터 캐시 미스율: 11.4%
• 결합된 캐시 미스율: 3.2%
• 결합된 미스율은 명령어와 데이터 액세스의 빈도를 고려한 가중 평균이다.
7. Split Cache(분리 캐시)의 장점
• 명령어와 데이터 캐시 분리:
• 명령어와 데이터가 병렬로 처리될 수 있어 캐시 대역폭이 증가한다.
• 현대 프로세서에서 일반적으로 사용되는 방식이다.
• 단점:
• 분리된 캐시 크기가 고정되어 있어 특정 워크로드에 따라 비효율이 발생할 수 있다.

Check Yourself 문제 풀이
질문:
메모리 시스템 속도가 캐시 블록 크기에 영향을 미칩니다. 다음 중 옳은 설계 가이드는 무엇인가?
1. 메모리 지연 시간이 짧을수록, 캐시 블록 크기는 작아야 한다.
2. 메모리 지연 시간이 짧을수록, 캐시 블록 크기는 커야 한다.
3. 메모리 대역폭이 높을수록, 캐시 블록 크기는 작아야 한다.
4. 메모리 대역폭이 높을수록, 캐시 블록 크기는 커야 한다.
정답:
• 4번이 맞다.
메모리 대역폭이 높으면 더 큰 블록을 한 번에 가져올 수 있으므로, 블록 크기를 크게 설정하여 성능을 최적화할 수 있다.
'Book > COMPUTER ORGANIZATION AND DESIGN RISC-V' 카테고리의 다른 글
| 5.5 Dependable Memory Hierachy (0) | 2024.12.02 |
|---|---|
| 5.4 Measuring and Improving Cache Performance (1) | 2024.12.02 |
| 5.2 Memory Technologies (0) | 2024.11.20 |
| 5. Large and Fast: Exploiting Memory Hierarchy(5.1 Introduction) (0) | 2024.11.20 |
| 4. The Processor (4.11 Parallelism via Instructions) (2) | 2024.11.17 |